Recently I took a stab at auditing a popular Firefox addon NoScript, which is fairly well known among the netsec and privacy community due to its bold functionality of blocking active content such as Flash, Java, and JavaScript on all sites by default. My goal was simply to bypass the addon when it’s been installed with the default configuration. This is partially because so many people put a lot of trust into NoScript and also because I hear a lot of people snubbing exploits because “I use NoScript when I browser the internet and am therefore safe from all web exploits!“. This attitude is annoying so having a bypass to pull people back into sanity sounded nice.
So, where to start?
As it turns out “NoScript” is something of a misnomer due to the addon shipping with a whitelist that explicitly allows a set of CDNs/popular sites. When you install NoScript you are explicitly trusting these sites to execute Java/Flash/JavaScript even when NoScript is set to forbid scripts globally.
So what is this list? You can check it yourself by going to NoScript > Options > Whitelist
The list includes the following:
addons.mozilla.org afx.ms ajax.aspnetcdn.com bootstrapcdn.com cdnjs.cloudflare.com code.jquery.com firstdata.com firstdata.lv flashgot.net gfx.ms google.com googleapis.com googlevideo.com gstatic.com hotmail.com informaction.com live.com live.net maone.net mootools.net mozilla.net msn.com noscript.net outlook.com passport.com passport.net passportimages.com paypal.com paypalobjects.com persona.org prototypejs.org securecode.com securesuite.net sfx.ms tinymce.cachefly.net vjs.zendcdn.net wlxrs.com yahoo.com yahooapis.com yandex.st yimg.com youtube.com ytimg.com about:blank http://afx.ms http://bootstrapcdn.com http://firstdata.com http://firstdata.lv http://flashgot.net http://gfx.ms http://google.com http://googleapis.com http://googlevideo.com http://gstatic.com http://hotmail.com http://informaction.com http://live.com http://live.net http://maone.net http://mootools.net http://mozilla.net http://msn.com http://noscript.net http://outlook.com http://passport.com http://passport.net http://passportimages.com http://paypal.com http://paypalobjects.com http://persona.org http://prototypejs.org http://securecode.com http://securesuite.net http://sfx.ms http://wlxrs.com http://yahoo.com http://yahooapis.com http://yandex.st http://yimg.com http://youtube.com http://ytimg.com https://afx.ms https://bootstrapcdn.com https://firstdata.com https://firstdata.lv https://flashgot.net https://gfx.ms https://google.com https://googleapis.com https://googlevideo.com https://gstatic.com https://hotmail.com https://informaction.com https://live.com https://live.net https://maone.net https://mootools.net https://mozilla.net https://msn.com https://noscript.net https://outlook.com https://passport.com https://passport.net https://passportimages.com https://paypal.com https://paypalobjects.com https://persona.org https://prototypejs.org https://securecode.com https://securesuite.net https://sfx.ms https://wlxrs.com https://yahoo.com https://yahooapis.com https://yandex.st https://yimg.com https://youtube.com https://ytimg.com
Quite the list!
But it’s not just these domains, it’s also the subdomains of any site without a preceding “http(s)://”.
For example, when you add example.com to your whitelist did you also know that you’re trusting every subdomain of that site as well? It’s not very obvious (it wasn’t to me!).
So thirdparty.example.com is completely trusted as well, even though you may have only meant the main example.com website. This greatly expands the default trust surface that you opt-in to when you install NoScript.
My plan was to enumerate all the subdomains of each whitelisted domain name and try to gain stored XSS on just one of them. However, my venture was cut short when I performed an NS query for each domain:
mandatory> dig NS zendcdn.net ; <<>> DiG 9.8.3-P1 <<>> NS zendcdn.net ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 21164 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0 ;; QUESTION SECTION: ;zendcdn.net. IN NS ;; AUTHORITY SECTION: net. 899 IN SOA a.gtld-servers.net. nstld.verisign-grs.com. 1434149433 1800 900 604800 86400 ;; Query time: 157 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: Fri Jun 12 15:50:54 2015 ;; MSG SIZE rcvd: 106
Wait a minute, an NXDOMAIN error? The domain doesn’t exist?
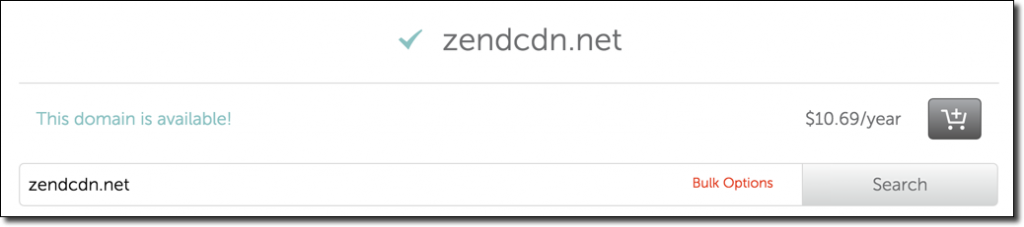
Apparently not.
I still thought that it can’t be that easy so I bought the domain for $10.69 (what a bargain) and then pointed the subdomain to a small JavaScript payload. Sure enough:
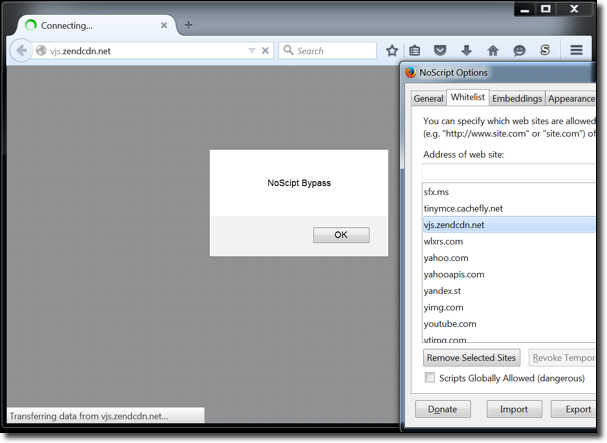
NoScript completely bypassed!
That was easy. But why in the world is this domain even in the whitelist anyways? As it turns out it’s due to a request by a user in this NoScript forum thread:
https://forums.informaction.com/viewtopic.php?f=10&t=17066
The user suggests a few popular CDNs following by the expired domain that I bought. Apparently zendcdn.net didn’t pass the test of time!
In fact, if you Google “zendcdn.net” the first result is literally the thread itself:
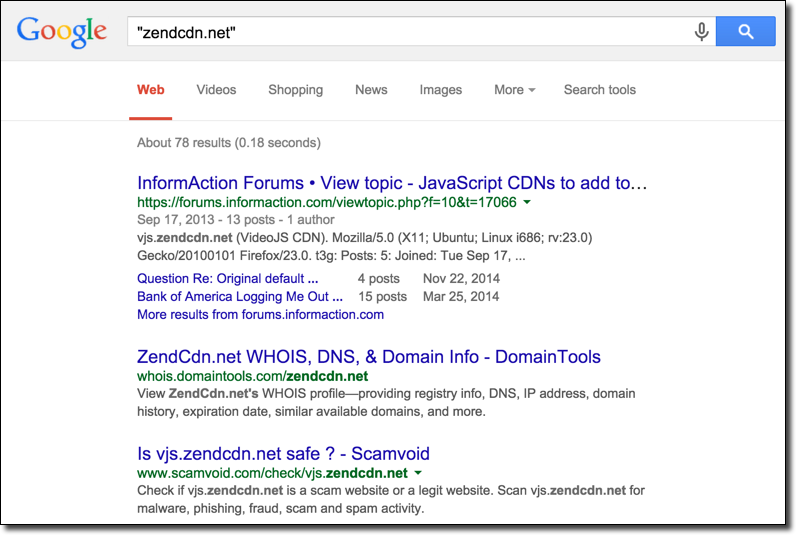
Totally legit.
While the journey was cut short due to early success it is interesting to think about. Do you trust every site in NoScript’s whitelist? What about their subdomains? If any domain or subdomain has stored XSS or some other vulnerability that allows an attacker to store arbitrary content on that server – NoScript is essentially useless! You are not only trusting these sites to be non-malicious you’re trusting them to be secure. Can you say that about every site in the default whitelist?
So, I encourage every reading this to please purge your whitelist. Remove everything you don’t trust! It’s fine to trust a site but make sure you understand what you’re doing. Keep in mind that when you trust example.com you’re actually trusting *.example.com (consider whitelisting http://example.com instead which doesn’t implicitly trust subdomains). Any stored-XSS on that site or its subdomains would allow an attacker to embed a JavaScript-based exploit to attack users with. It is my opinion that universal bypasses for NoScript should actually be quite easy to find since the default whitelist exposes so much surface area.
I contacted Giorgio Maone about the vulnerability and the response time was incredibly quick. Within hours he had a patch out on his site and less then two days later the patch was pushed to all NoScript users. This is by far some of the fastest response and patch times I’ve ever seen – so hats off to him for that! Please note: This stray domain is no longer in the default whitelist for NoScript users.
Until next time,
-mandatory