In a past piece of research, we explored the issue of nameserver domains expiring allowing us to take over full control of a target domain. In that example we took over the domain name maris.int by buying an expired domain name which was authoritative for the domain. This previous example happened to have two broken nameservers, one being misconfigured and the other being an expired domain name. Due to this combination of issues the domain was totally inaccessible (until I bought the domain and reserved/rehosted the old website again). While this made it easier to take full control of the DNS of the domain (since most clients will automatically fail over to the working nameserver(s)), it also raises an important question. Are there other domains where only some of the nameservers are not working due to them having an expired domain name or some other takeover vulnerability? After all, as discussed in previous posts there are many, different, ways, for a nameserver to become vulnerable to takeover.
A Few Bad Nameservers
In an effort to find a proof-of-concept domain which suffered from having just a few of its nameservers vulnerable to takeover I had to turn back to scanning the Internet. Luckily, since we have an old copy of the .int zone we can start there. After iterating through this list I was able to find yet another vulnerable .int domain: iom.int. This website is totally functional and working but two of its nameservers are actually expired domain names. Interestingly enough, unless you traverse the DNS tree you likely won’t even notice this issue. For example, here’s the output for an NS query against iom.int:
mandatory@script-srchttpsyvgscript ~> dig NS iom.int ; <<>> DiG 9.8.3-P1 <<>> NS iom.int ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 9316 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 0 ;; QUESTION SECTION: ;iom.int. IN NS ;; ANSWER SECTION: iom.int. 86399 IN NS ns1.gva.ch.colt.net. iom.int. 86399 IN NS ns1.zrh1.ch.colt.net. ;; Query time: 173 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: Thu Dec 8 14:12:47 2016 ;; MSG SIZE rcvd: 81
As we can see from the above output we’ve asked the resolver 8.8.8.8 (Google’s public resolver) for the nameservers of iom.int and it has returned to us ns1.zrh1.ch.colt.net. and ns1.gva.ch.colt.net. with NOERROR as the status. The domain name colt.net is not available and is currently registered, working, and returning DNS records as expected. If this is the case how is this domain vulnerable? It turns out that we are being slightly misled due to the way that dig works. Let’s break down what is happening with dig’s +trace flag:
mandatory@script-srchttpsyvgscript ~> dig iom.int +trace ; <<>> DiG 9.8.3-P1 <<>> iom.int +trace ;; global options: +cmd . 209756 IN NS g.root-servers.net. . 209756 IN NS m.root-servers.net. . 209756 IN NS i.root-servers.net. . 209756 IN NS l.root-servers.net. . 209756 IN NS f.root-servers.net. . 209756 IN NS b.root-servers.net. . 209756 IN NS c.root-servers.net. . 209756 IN NS h.root-servers.net. . 209756 IN NS d.root-servers.net. . 209756 IN NS k.root-servers.net. . 209756 IN NS j.root-servers.net. . 209756 IN NS e.root-servers.net. . 209756 IN NS a.root-servers.net. ;; Received 228 bytes from 172.16.0.1#53(172.16.0.1) in 30 ms int. 172800 IN NS ns.icann.org. int. 172800 IN NS ns1.cs.ucl.ac.uk. int. 172800 IN NS ns.uu.net. int. 172800 IN NS ns0.ja.net. int. 172800 IN NS sec2.authdns.ripe.net. ;; Received 365 bytes from 192.5.5.241#53(192.5.5.241) in 88 ms iom.int. 86400 IN NS ns1.iom.org.ph. iom.int. 86400 IN NS ns2.iom.org.ph. iom.int. 86400 IN NS ns1.gva.ch.colt.net. iom.int. 86400 IN NS ns1.zrh1.ch.colt.net. ;; Received 127 bytes from 128.86.1.20#53(128.86.1.20) in 353 ms iom.int. 86400 IN A 54.154.14.101 iom.int. 86400 IN NS ns1.zrh1.ch.colt.net. iom.int. 86400 IN NS ns1.gva.ch.colt.net. ;; Received 97 bytes from 212.74.78.22#53(212.74.78.22) in 172 ms
This shows us dig’s process as it traverses the DNS tree. First we can see it asks the root nameservers for the nameservers of the .int TLD. This gives us results like ns.icann.org, ns1.cs.ucl.ac.uk. etc. Next dig asks one of the returned .int nameservers at random for the nameservers of our target iom.int domain. As we can see from this output there are actually more nameservers which the .int TLD nameservers are recommending to us. However, despite dig receiving these nameservers it hasn’t yet gotten what its looking for. Dig will continue down the delegation chain until it gets an authoritative response. Since the .int TLD nameservers are not authoritative for the iom.int zone they don’t set the authoritative answer flag on the DNS response. DNS servers are supposed to set the authoritative answer flag when they are the owner of a specific zone. This is DNS’s way of saying “stop traversing the DNS tree, I’m the owner of the zone you’re looking for – ask me!”. Completing dig’s walk we see that it picks a random nameserver returned by the .int TLD nameservers and asks it what the nameservers are for the iom.int domain. Since these nameservers are authoritative for the iom.int zone dig takes this answer and returns it to us. Interestingly enough, if dig had encountered some of the non-working nameservers, specifically ns1.iom.org.ph and ns2.iom.org.ph it would simply have failed over to one of the working colt.net nameservers without letting us know.
Domain Availability, Registry Truth & Sketchy DNS Configurations
Note: This is an aside from the main topic, feel free to skip this section if you don’t want to read about .org.ph DNS sketchiness.
When I initially scanned for this vulnerability using some custom software I’d written, I received an alert that iom.org.ph was available for registration. However when I queried for the domain using dig I found something very odd:
mandatory@script-srchttpsyvgscript ~> dig A iom.org.ph ; <<>> DiG 9.8.3-P1 <<>> A iom.org.ph ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 18334 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0 ;; QUESTION SECTION: ;iom.org.ph. IN A ;; ANSWER SECTION: iom.org.ph. 299 IN A 45.79.222.138 ;; Query time: 54 msec ;; SERVER: 172.16.0.1#53(172.16.0.1) ;; WHEN: Sat Dec 17 23:35:00 2016 ;; MSG SIZE rcvd: 51
The above query shows that when we look up the A record (IP address) for iom.org.ph we get a valid IP back. So, wait, iom.org.ph is actually responding with a valid record? How are we getting back an A record if the domain doesn’t exist? Things get even more weird when you ask what the nameservers are for the domain:
mandatory@script-srchttpsyvgscript ~> dig NS iom.org.ph ; <<>> DiG 9.8.3-P1 <<>> NS iom.org.ph ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 18589 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0 ;; QUESTION SECTION: ;iom.org.ph. IN NS ;; AUTHORITY SECTION: ph. 899 IN SOA ph-tld-ns.dot.ph. sysadmin.domains.ph. 2016121814 21600 3600 2592000 86400 ;; Query time: 60 msec ;; SERVER: 172.16.0.1#53(172.16.0.1) ;; WHEN: Sat Dec 17 23:34:50 2016 ;; MSG SIZE rcvd: 102
According to dig no nameservers are returned for our domain despite us getting an A record back just a moment ago. How can this be? After trying this query I was even less confident the domain was available at all, so I issued the following query to sanity check myself:
mandatory@script-srchttpsyvgscript ~> dig A ThisCantPossiblyExist.org.ph ; <<>> DiG 9.8.3-P1 <<>> A ThisCantPossiblyExist.org.ph ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 65010 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0 ;; QUESTION SECTION: ;ThisCantPossiblyExist.org.ph. IN A ;; ANSWER SECTION: ThisCantPossiblyExist.org.ph. 299 IN A 45.79.222.138 ;; Query time: 63 msec ;; SERVER: 172.16.0.1#53(172.16.0.1) ;; WHEN: Sat Dec 17 23:39:24 2016 ;; MSG SIZE rcvd: 62
Ok so apparently all .org.ph domains which don’t exist return an A record. What in the world is at that IP?! The following is a screenshot of what we get when we go to ThisCantPossiblyExist.org.ph:
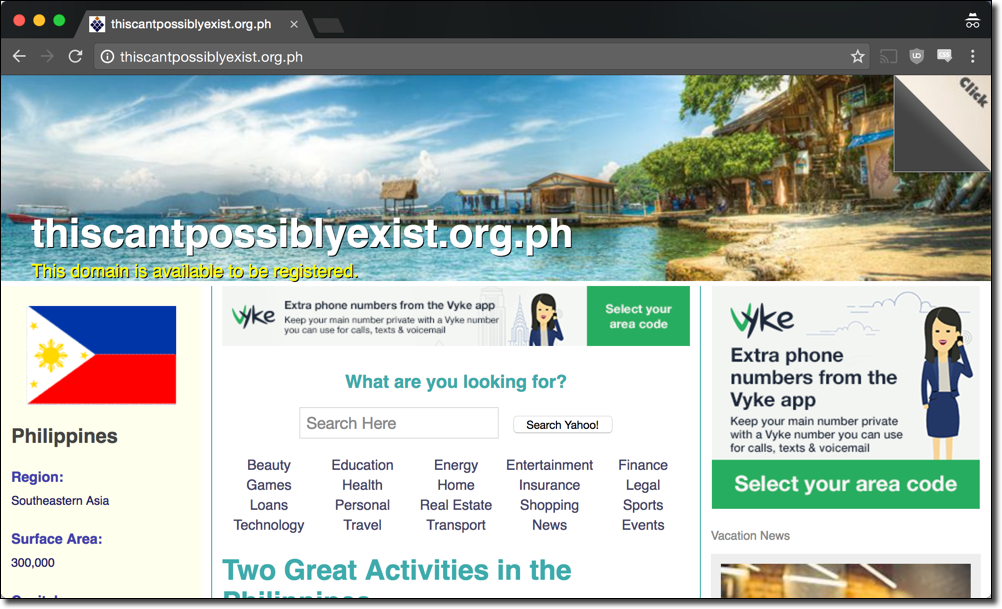
The above makes it fairly clear what’s happening. Instead of simply failing to resolve, the .org.ph TLD nameservers return us an A record to a page filled with questionable advertisements as well as a notice that says “This domain is available to be registered”. Likely this is to make a little extra money from people attempting to visit non-existent domains. I’ll refrain from commenting on the ethics or sketchiness of this tactic and stick to how you can detect this with dig. The following query reveals how this is set up:
mandatory@script-srchttpsyvgscript ~> dig ANY '*.org.ph' ; <<>> DiG 9.8.3-P1 <<>> ANY *.org.ph ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 51271 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0 ;; QUESTION SECTION: ;*.org.ph. IN ANY ;; ANSWER SECTION: *.org.ph. 299 IN A 45.79.222.138 ;; Query time: 50 msec ;; SERVER: 172.16.0.1#53(172.16.0.1) ;; WHEN: Sat Dec 17 23:49:15 2016 ;; MSG SIZE rcvd: 42
The above query shows that there is a wildcard A record set up for anything that matched *.org.ph. This is why we saw this behaviour.
For an additional sanity check one powerful tool which is always useful is historical data on domains. One of the largest collectors of historical DNS, WHOIS, and general Internet data that I know of is Domain Tools. After reaching out they were kind enough to provide a researcher account for me so I used there database to get the full story of vulnerabilities such as this one. Querying their dataset we can understand when exactly this iom.org.ph domain became vulnerable (expired) in the first place.
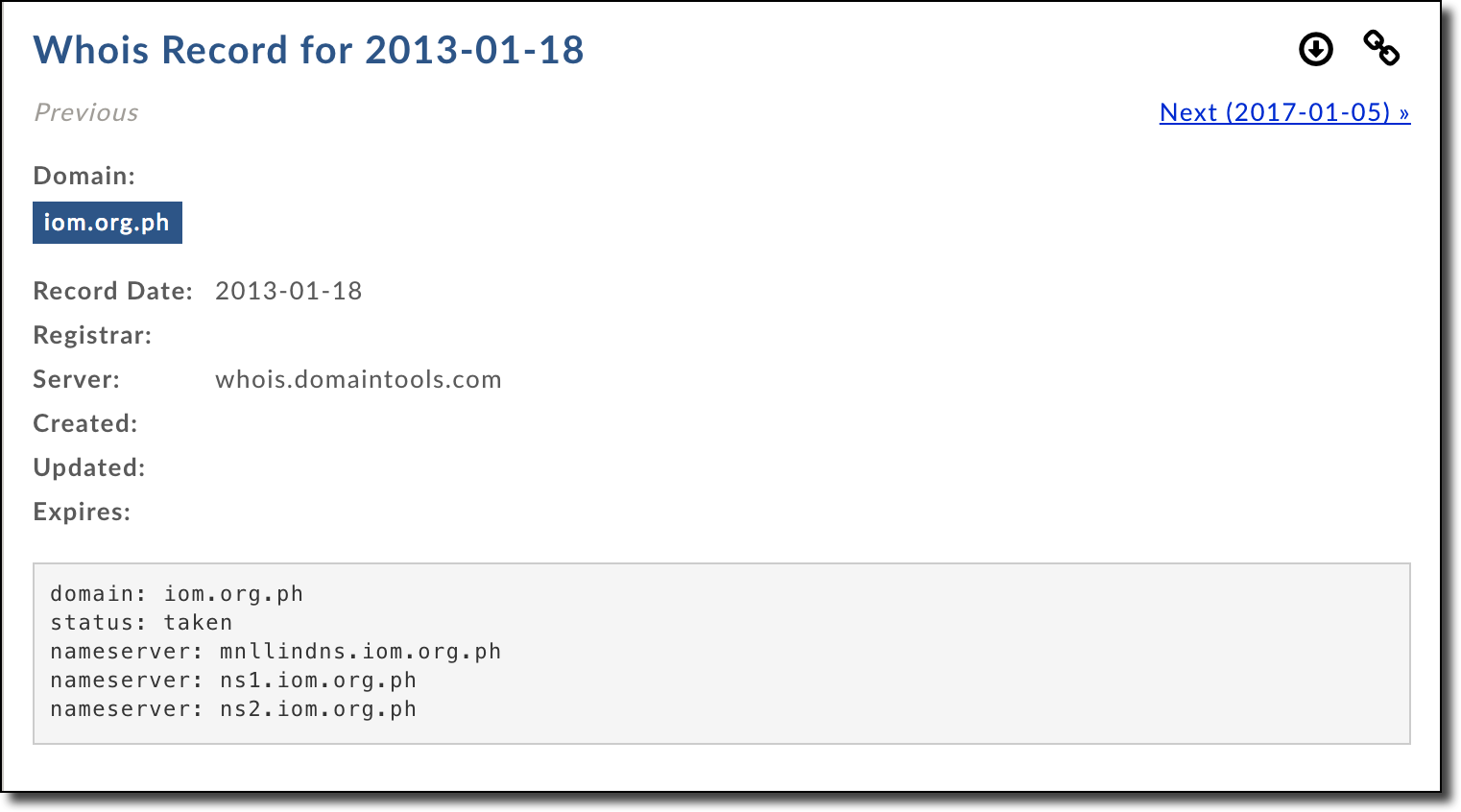
Interestingly enough, this historical data shows that this domain has likely been expired since 2013. The fact that this issue could have existed for this long shows that this type of vulnerability is subtle enough to go unnoticed for a long time (~4 years!). Crazy.
Back to the Takeover
Moving back to our takeover, once I realized that iom.org.ph was indeed available I was able to register it and become an authoritative nameserver for iom.int. This is similar to the maris.int example but with an interesting caveat. When someone attempts to visit iom.int there is about a 50% chance that our nameservers will be queried instead of the authentic ones. The reason for this is due to Round Robin DNS which is a technique used in DNS to distribute load across multiple servers. The concept is fairly simple, in DNS you can return multiple records for a query if you want to distribute the load across a few servers. Since you want to distribute load evenly you will return these records in a random order so that querying clients will choose a different record each time they request it. In the case of a DNS A record this would mean that if you returned three IP addresses in a random order, you should see that each IP address is used by your users roughly 33.33% of the time. We can see this in action if we attempt a few NS queries for iom.int directly at the .int TLD nameservers. We get the .int TLD nameservers by doing the following:
mandatory@script-srchttpsyvgscript ~> dig NS int. ; <<>> DiG 9.8.3-P1 <<>> NS int. ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 54471 ;; flags: qr rd ra; QUERY: 1, ANSWER: 5, AUTHORITY: 0, ADDITIONAL: 0 ;; QUESTION SECTION: ;int. IN NS ;; ANSWER SECTION: int. 52121 IN NS ns.uu.net. int. 52121 IN NS ns.icann.org. int. 52121 IN NS ns0.ja.net. int. 52121 IN NS ns1.cs.ucl.ac.uk. int. 52121 IN NS sec2.authdns.ripe.net. ;; Query time: 38 msec ;; SERVER: 172.16.0.1#53(172.16.0.1) ;; WHEN: Sun Dec 18 00:23:29 2016 ;; MSG SIZE rcvd: 153
We’ll pick one of these at random (ns.uu.net) and ask for the nameservers of iom.int a few times:
mandatory@script-srchttpsyvgscript ~> dig NS iom.int @ns.uu.net. ; <<>> DiG 9.8.3-P1 <<>> NS iom.int @ns.uu.net. ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 41151 ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 0 ;; WARNING: recursion requested but not available ;; QUESTION SECTION: ;iom.int. IN NS ;; AUTHORITY SECTION: iom.int. 86400 IN NS ns1.iom.org.ph. iom.int. 86400 IN NS ns1.gva.ch.colt.net. iom.int. 86400 IN NS ns2.iom.org.ph. iom.int. 86400 IN NS ns1.zrh1.ch.colt.net. ;; Query time: 76 msec ;; SERVER: 137.39.1.3#53(137.39.1.3) ;; WHEN: Sun Dec 18 00:23:35 2016 ;; MSG SIZE rcvd: 127 mandatory@script-srchttpsyvgscript ~> dig NS iom.int @ns.uu.net. ; <<>> DiG 9.8.3-P1 <<>> NS iom.int @ns.uu.net. ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 14215 ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 0 ;; WARNING: recursion requested but not available ;; QUESTION SECTION: ;iom.int. IN NS ;; AUTHORITY SECTION: iom.int. 86400 IN NS ns1.gva.ch.colt.net. iom.int. 86400 IN NS ns2.iom.org.ph. iom.int. 86400 IN NS ns1.zrh1.ch.colt.net. iom.int. 86400 IN NS ns1.iom.org.ph. ;; Query time: 79 msec ;; SERVER: 137.39.1.3#53(137.39.1.3) ;; WHEN: Sun Dec 18 00:23:36 2016 ;; MSG SIZE rcvd: 127 mandatory@script-srchttpsyvgscript ~> dig NS iom.int @ns.uu.net. ; <<>> DiG 9.8.3-P1 <<>> NS iom.int @ns.uu.net. ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 31489 ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 0 ;; WARNING: recursion requested but not available ;; QUESTION SECTION: ;iom.int. IN NS ;; AUTHORITY SECTION: iom.int. 86400 IN NS ns2.iom.org.ph. iom.int. 86400 IN NS ns1.zrh1.ch.colt.net. iom.int. 86400 IN NS ns1.gva.ch.colt.net. iom.int. 86400 IN NS ns1.iom.org.ph. ;; Query time: 87 msec ;; SERVER: 137.39.1.3#53(137.39.1.3) ;; WHEN: Sun Dec 18 00:23:37 2016 ;; MSG SIZE rcvd: 127
As can be seen above, each time we ask we get the nameservers in a different order. This is the beauty of round robin DNS since each nameserver will receive roughly equal load of DNS queries. However this complicates our attack because half of the time users will be querying the legitimate nameservers! So the question now becomes how can we tip the odds in our favor?
May the RR Odds Be Ever in Our Favor
So, we can’t control the behaviour of the .int TLD servers and we’ll only be chosen approximately 50% of the time. As an attacker we need to figure out how to make that closer to 100%. Luckily, due to how DNS is structured, we can get very close.
When you visit www.google.com and your computer does a DNS lookup for that record, it likely isn’t going to traverse the entire DNS tree to get the result. Instead it likely makes use of a DNS resolver which will perform this process on your behalf while caching all of the results. This resolver is assigned to your computer during the DHCP process and can be either a large shared resolver (such as 8.8.8.8, or 8.8.4.4) or a small resolver hosted on your local router or computer. The idea behind the resolver is that it can serve many clients making DNS requests and can speed up resolution by caching results. So if one client looks up www.google.com and shortly after another client does the same, the DNS tree doesn’t have to be traversed because the resolver already has a cached copy. The important point to realize here is that in DNS, caching is king. The side effects of this architecture are made more apparent when events like the DDoS attacks against Dyn that knocked the Internet offline for millions of users happen. As it turns out when you put all your eggs in one basket, you’d better be sure the basket can hold up.
Caching is accomplished by DNS resolvers temporarily storing the results of a DNS query for whatever the response’s TTL has been set to. This means that if a response has a TTL of 120, for example, the caching resolver likely will obey this and return this same record for two minutes. There are upper limits to this value, but its resolver-dependent and likely can be set as long as a week without problems.
Given this situation, we can win this game by setting longer TTLs that our legitimate servers for all of our authoritative responses. The situation essentially boils down into this:
- User looks up the A record for iom.int to visit the site.
- Due to the random choosing of nameservers from the .int TLD NS query results, the user has a 50% chance of choosing our poisoned nameserver.
- Say the user doesn’t choose us and gets the legit nameservers, their resolver will record this result and cache it for the specified TTL of 21,745 seconds (approximately 6 hours). This is the current TTL for this record at the time of this writing.
- Later on, the user attempts to visit the website after more than 6 hours have passed, again they traverse this tree but this time they get one of our malicious nameservers which we’ve taken over. We reply with a TTL of 604,800 seconds (one week), or with an even longer TTL depending on what we think we can get away with. The user’s cache records this value and will hold it for the length of the TTL we specified.
- Now for an entire week the user, and, more importantly, all the other clients of the resolver will always use our falsified record.
This example becomes more extreme when you realize that many people and services make use of large resolvers like Google’s public resolvers (8.8.8.8, 8.8.4.4) or Dyn’s (216.146.35.35, 216.146.36.36). On this level its only a matter of time until the resolver picks our poisoned nameservers and we can poison all clients of this resolver (potentially millions) for a long period of time. Even better, with large resolvers we can easily test to see if we’ve succeeded and can act quickly when we know we’ve poisoned the community cache.
The Power of DNS
So, we now can poison the DNS for our target – but what power does this give us? What can we do with our newly gained priveleges?
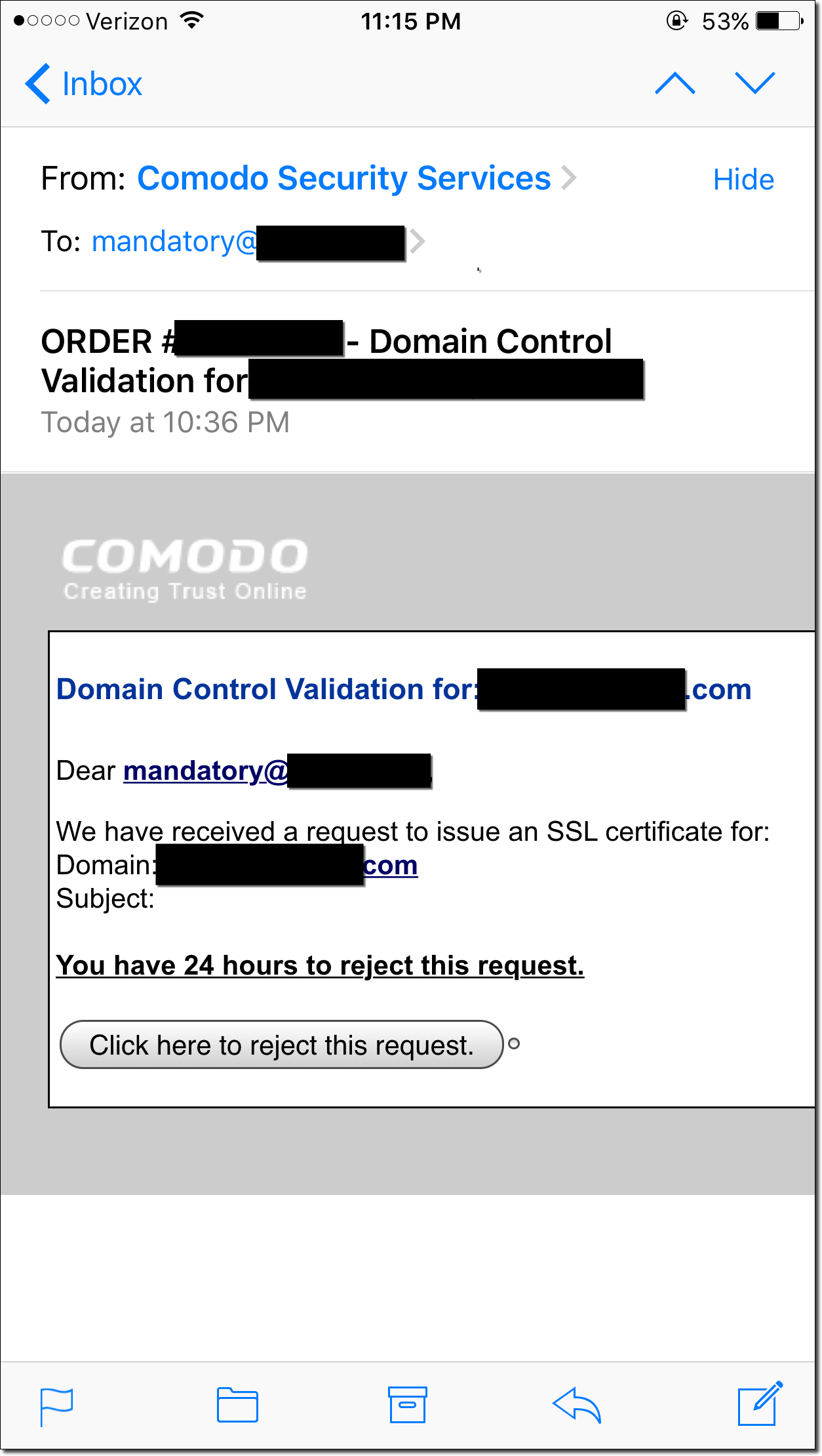
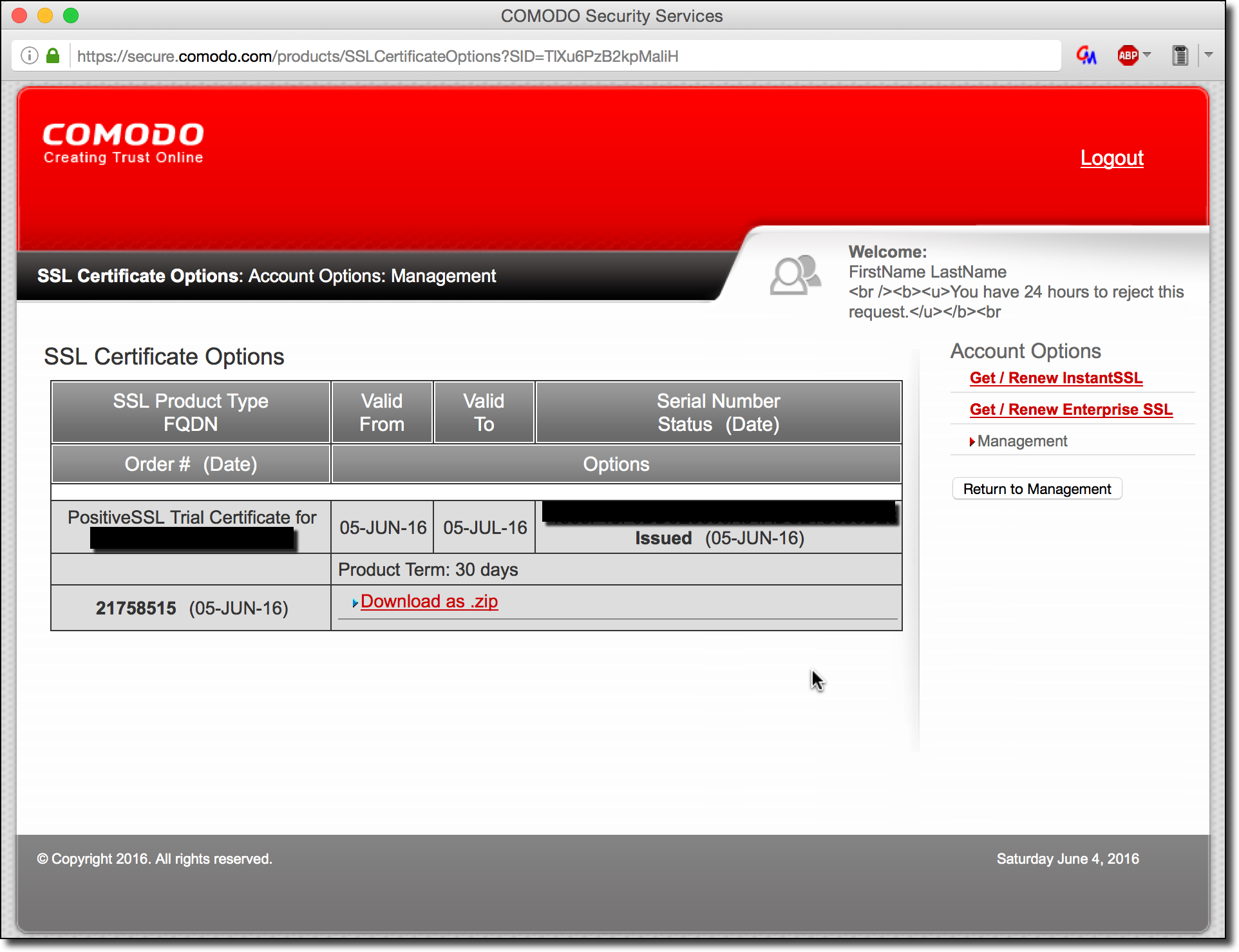
- Issue arbitrary SSL/TLS certificates for iom.int: Due to the fact that many certificate authorities allow either DNS, HTTP, or email for domain name verification, we can easily set DNS records for servers we control to prove we own the target domain. Even if the CA chooses our target’s nameservers instead of ours, we can simply request again once the cache expired until they eventually ask our malicious nameservers. This assumes the certificate authority’s certificate issuing system actually performs caching – if it doesn’t we can simply immediately try again until our malicious servers are picked.
- Targeted Email Interception: Since we can set MX records for our targets, we can set up our malicious servers to watch for DNS requests from specific targets like GMail, Yahoo Mail, or IANA’s mail servers and selectively lie about where to route email. This gives us the benefit of stealth because we can give legitimate responses to everyone querying except for the targets we care about.
- Takeover of the .int Domain Name Itself: In the case of the .int TLD, if we want to change the owners or the nameservers of this domain at the registry, both the Administrative contact and the Technical contact must approve this change (assuming the policy is the same as IANA’s policy for root nameserver changes which IANA also manages). You can see the example form here on IANA’s website. Since both of the email addresses on the WHOIS are at iom.int as well, so we have the ability to intercept mail for both. We can now wait until we see an MX DNS request from IANA’s IP range and selectively poison the results to redirect the email to our servers, allowing us to send and receive emails as the admin. Testing to see if IANA’s mail servers have been poisoned can be achieved by spoofing emails from iom.int and checking if the bounce email is redirected to our malicious mail servers. If we don’t receive it we simply wait until the TTL of the legit mail servers is over and try again.
- Easily Phish Credentials: Since we can change DNS we can rewrite the A records to point to our own phishing servers in order to steal employee credentials/etc.
- MITM Devices via SRV Spoofing: Since we can also control SRV records, we can change these to force embedded devices to connect to our servers instead. This goes for any service which uses DNS for routing (assuming no other validation method is built into the protocol).
- And much more…
So clearly this is a vulnerability which can occur but does it occur often? Sure maybe one random .int website has this vulnerability but do any actually important websites suffer from this issue?
Not An Isolated Incident
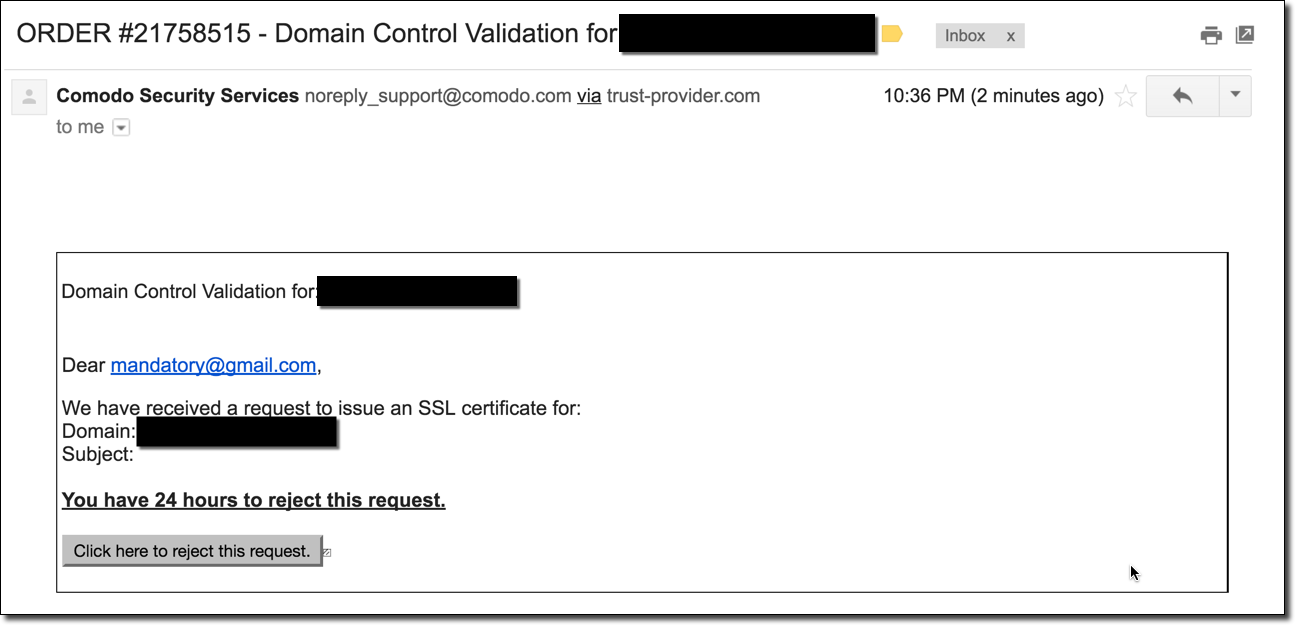
The following is a screenshot from another website which was found to suffer from this same vulnerability as iom.int. This time from something as simple as a typo in the nameserver hostname:
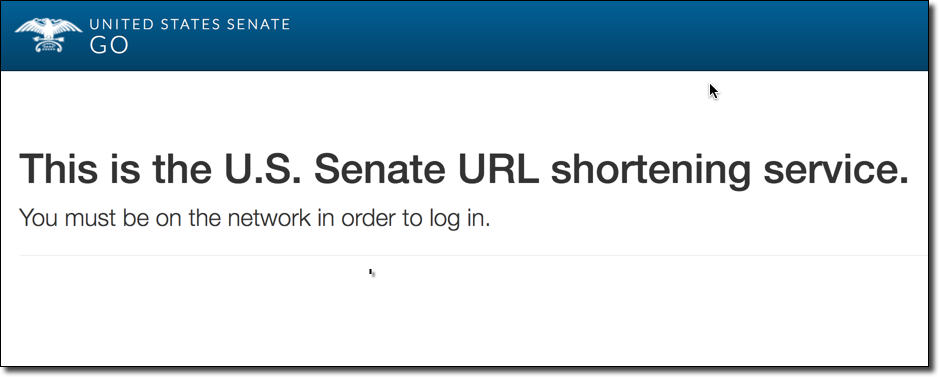
The vulnerable domain was sen.gov an internal URL shortening service for the United States Senate. The domain had a non-existent domain of ns1-201-akam.net set as an authoritative nameserver. This was likely a typo of ns1-201.akam.net which is a sub-domain belonging to Akamai, this slight mistype has caused a massive security issue where you want it the least. Since the site’s very purpose is to redirect what is assumedly members of the US Senate to random sites from links sent by other members it would be a goldmine for an attacker wishing to do malicious DNS-based redirection for a drive-by exploitation or targeted phishing attacks. Due to the high risk and trivial exploitability of the issue I purchased the nameserver domain myself and simply blocked DNS traffic to that domain (allowing the DNS queries to fail over to the remaining working servers). This essentially “plugged” the issue until it could be fixed by the administrators of the site. Shortly after this I reached out to the .gov registry who forwarded my concerns to the site’s administrators who fixed the issue extremely quickly (see disclosure timeline below). All said and done very impressive response time! This does, however, highlight that this type of issue can happen to anyone. In addition to these two examples outlined here many more exist which are not listed (for obvious reasons), demonstrating that this is not an isolated issue.
Disclosure Timeline
International Organization for Immigration (iom.int) Disclosure
- Dec 09, 2016: Contacted ocu@ with a request to disclose this issue (contact seemed appropriate per their website).
- Dec 23, 2016: Due to lack of response forwarded previous email to WHOIS contacts.
- Dec 23, 2016: Received response from Jackson (Senior Information Security Officer for iom.int) apologizing for missing the earlier email and requesting details of the problem.
- Dec 23, 2016: Disclosed issue via email.
- Dec 23, 2016: Confirmed receipt of issue, stating that the problem and implications are understood. States that it will be addressed internally and that an update will be sent when it has been fixed.
- Dec 27, 2016: Update received from Jackson stating that IANA has been contacted and instructed to remove any reference to the domain iom.org.ph in order to remediate the vulnerability. IANA states that this can take up to five business days to accomplish.
- Dec 27, 2016: Asked if Jackson would also like the iom.org.ph domain name back or if it should be left to expire.
- Dec 27, 2016: Jackson confirms the domain name is no longer needed and it’s fine to let it expire.
Disclosure Notes: I got a quick response once I forwarded the info to the correct contacts, I should’ve gone for the broader CC with this disclosure and will have to keep that in mind for future disclosures. Didn’t expect such a quick response (or even a dedicated security person) so it was a nice surprise to have Jackson jump on the problem so fast.
United States Senate (sen.gov) Disclosure
- January 5, 2017: Reached out to .gov registry requesting responsible disclosure and offering PGP.
- January 6, 2017: Response received from help desk stating they can forward any concerns to the appropriate contacts if needed.
- January 6, 2017: Disclosed issue to help desk.
- January 8, 2017: Nameserver patch applied, all nameservers are now correctly set!
Disclosure Notes: Again, didn’t expect a quick patch like this and was blown away with how quickly this was fixed (less than two days!). In the past government agencies I’ve reported vulnerabilities to have been a super slow process to apply a patch so this was a breathe of fresh air. Really impressed!
Judas DNS – A Tool For Exploiting Nameserver Takeovers
In order to make the process of exploiting this unique type of vulnerability easier I’ve created a proof-of-concept malicious authoritative nameserver which can be used once you’ve taken over a target’s nameserver. The Judas server proxies all DNS requests to the configured legitimate authoritative nameservers while also respecting a custom ruleset to modify DNS responses if certain rule-matching criteria is met. For more information on how it works as well as the full source code see the below link:
Judas DNS Github
Closing Thoughts
This vulnerability has all the trademarks of being a dangerous security issue. Not only is it an easy mistake to make via a typo or an expired nameserver domain, it also does not present any immediately obvious problems for availability due to the failover nature of many DNS clients. This means that not only can it happen to anyone, it means it can also go unnoticed for a long time.
On the topic of remediation, this issue is interesting because it could possibly be mitigated at the TLD-level. If TLD operators did simple DNS health checks to ensure that all domain nameservers had at least the possibility of working (e.g. doing a simple A lookup occasionally to check if an IP address is returned, or look for NXDOMAIN) they could likely prevent this class of hijacking altogether. However, I suspect this would be a heavy handed thing for TLDs to take on and could potentially be prone to error (what about nameservers that only serve private/internal network clients?). After all, if a TLD was to automatically remove nameservers of suspected vulnerable domains and it caused an outage, there would certainly be hell to pay. Still, there is definitely an interesting discussion to be had on how to fix these vulnerabilities at scale.
Credit
Thanks to @Baloo and @kalou000 at Gandi.net for being extremely helpful resources on DNS/Internet-related information. Not many people can quote obscure DNS functionality off-hand so being able to bounce ideas off of them was invaluable. Additionally for providing enterprise access to their domain-checking API for security research purposes (such as this project!). This was amazing for checking domain existence because Gandi (as far as I’m aware), has the largest TLD support of any registrar so they were perfect for this research (Nicaragua? Philippines? Random country in Africa? Yep, TLD supported).
Until next time,
-mandatory

 from the Tor folks – thanks guys/gals!
from the Tor folks – thanks guys/gals!