I will liken him to a wise man, who built his house on a rock. The rain came down, the floods came, and the winds blew, and beat on that house; and it didn’t fall, for it was founded on the rock. Everyone who hears these words of mine, and doesn’t do them will be like a foolish man, who built his house on the sand. The rain came down, the floods came, and the winds blew, and beat on that house; and it fell—and great was its fall.
The Parable of the Wise and Foolish Builders
{.passage-display}
Domain names are the foundation of the Internet that we all enjoy. However, despite the amount of people that use them very few understand how they work behind the scenes. Due to many layers of abstraction and various web services many people are able to own a domain and set up an entire website without knowing anything about DNS, registrars, or even WHOIS. While this abstraction has a lot of very positive benefits it also masks a lot of important information from the end customer. For example, many registrars are more than happy to advertise a .io domain name to you but how many .io owners actually know who owns and regulates .io domains? I don’t think it’s a large stretch to say that most domain owners know little to nothing about the entities behind their domain name. The question that is asked even less is “What is this domain extension’s track record for security?”.
A Quick Introduction to the DNS Structure
Feel free to skip this section if you already know how DNS works and is delegated.
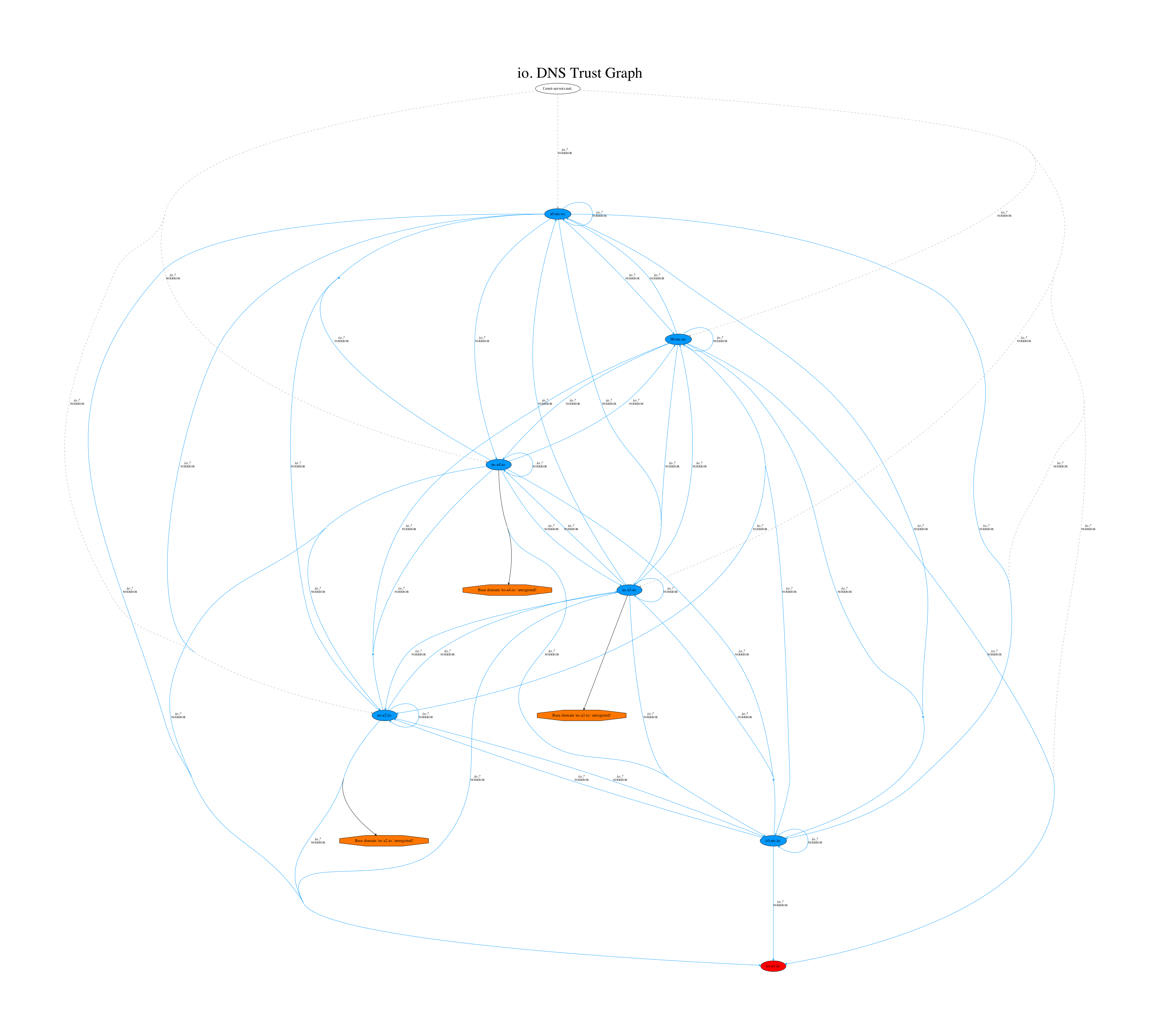
So what are you buying when you purchase a domain name? At a core, you’re simply buying a few NS (nameserver) records which will be hosted on the extension’s nameservers (this of course excludes secondary services such as WHOIS, registry/registrar operational costs, and other fees which go to ICANN). To better understand extension’s place in the chain of DNS we’ll take a look at a graph of example.com‘s delegation chain. I’ve personally found that visualization is very beneficial when it comes to understanding how DNS operates so I’ve written a tool called TrustTrees which builds a graph of the delegation paths for a domain name:
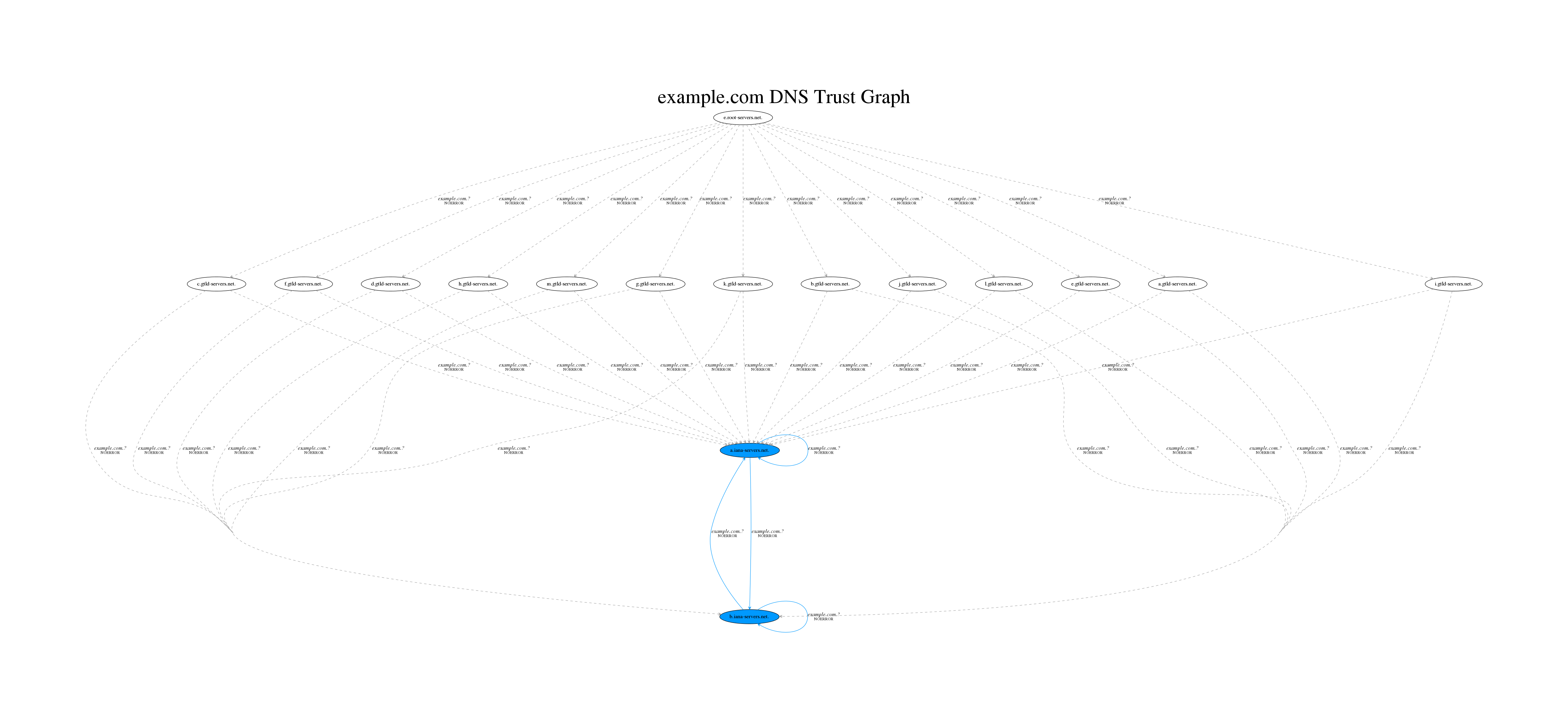 The above graph shows the delegation chain starting at the root level DNS server. For those unfamiliar with the DNS delegation process, it works via a continual chain of referrals until the target nameserver has been found. A client looking for the answer to a DNS query will start at the root level, querying one of the root nameservers for the answer to a given DNS query. The roots of course likely don’t know the answer and will delegate the query to a TLD, which will in turn delegate it to the appropriate nameservers and so on until an authoritative answer has been received confirming that the nameserver’s response is from the right place. The above graph shows all of the possible delegation paths which could take place (blue indicates an authoritative answer). There are many paths because DNS responses contain lists of answers in an intentionally random order (a technique known as Round Robin DNS) in order to provide load balancing for queries. Depending on the order of the results returned different nameservers may be queried for an answer and thus they may provide different results altogether. The graph shows all these permutations and shows the relationships between all of these nameservers.
The above graph shows the delegation chain starting at the root level DNS server. For those unfamiliar with the DNS delegation process, it works via a continual chain of referrals until the target nameserver has been found. A client looking for the answer to a DNS query will start at the root level, querying one of the root nameservers for the answer to a given DNS query. The roots of course likely don’t know the answer and will delegate the query to a TLD, which will in turn delegate it to the appropriate nameservers and so on until an authoritative answer has been received confirming that the nameserver’s response is from the right place. The above graph shows all of the possible delegation paths which could take place (blue indicates an authoritative answer). There are many paths because DNS responses contain lists of answers in an intentionally random order (a technique known as Round Robin DNS) in order to provide load balancing for queries. Depending on the order of the results returned different nameservers may be queried for an answer and thus they may provide different results altogether. The graph shows all these permutations and shows the relationships between all of these nameservers.
So, as discussed above, if you bought example.com the .com registry would add a few NS records to its DNS zones which would delegate any DNS queries for example.com to the nameservers you provided. This delegation to your nameservers is what really gives you control over the domain name and the ability to make arbitrary sub-domains and DNS records for example.com. If the .com owning organization decided to remove the nameserver (NS) records delegating to your nameservers then nobody would ever reach your nameservers and thus example.com would cease to work at all.
Taking this up a step in the chain you can think of TLDs and domain extensions in much the same way as any other domain name. TLDs only exist and can operate because the root nameservers delegate queries for them to the TLD’s nameservers. If the root nameservers suddenly decided to remove the .com NS records from its zone database then all .com domain names would be in a world of trouble and would essentially cease to exist.
Just Like Domain Names, Domain Name Extensions Can Suffer From Nameserver Vulnerabilities
Now that we understand that TLDs and domain extensions have nameservers just like regular domain names, one question that comes up is “Does that mean that TLDs and domain extensions can suffer from DNS security issues like domain names do?“. The answer, of course, is yes. If you’ve seen some of the past posts in this blog you’ve seen that we’ve learned that we can hijack nameservers in a variety of ways. We’ve shown how an expired or typo-ed nameserver domain name can lead to hijacking and we’ve also seen how many hosted DNS providers allow for gaining control over a domain’s zone without any verification of ownership. Taking the lessons we’ve learned from these explorations we can apply the same knowledge to attempt a much more grandiose feat: taking over an entire domain extension.
The Mission to Take Over a Domain Extension – The Plan of Attack
Unlike a malicious actor I’m unwilling to take many of the actions which would likely allow you to quickly achieve the goal of hijacking a domain extension. Along the course of researching methods for attacking domain extensions I found that many extension/TLD nameservers and registries are in an abysmal state to begin with, so exploiting and gaining control over one is actually much easier than many would think. Despite me considering tactics like obtaining remote code execution on a registry/nameserver to be out of scope I will still mention them as a viable route to success, since real world actors will likely have little regard for ethics.
Generally speaking, the following are some ways that I came up with for compromising a TLD/domain extension:
- Exploit a vulnerability in the DNS server which hosts a given domain extension or exploit any other services hosted on an extension’s nameservers. Attacking registries also falls into this same category as they have the ability to update these zones as part of normal operation.
- Find and register an expired or typo-ed nameserver domain which is authoritative for a domain extension/TLD.
- Hijacking the domain extension by recreating a DNS zone in a hosted provider which no longer has the zone for the extension hosted there.
- Hijacking the email addresses associated with a TLD’s WHOIS contact information (as listed in the IANA root zone database).
We’ll go over each of these and talk about some of the results found while investigating these avenues as possible routes to our goal.
Vulnerable TLD & Domain Extension Nameservers Are Actually Quite Common
To begin researching the first method of attack, I decided to do a simple port scan of all of the TLD nameservers. In a perfect world what you would like to see is a list of servers listening on UDP/TCP port 53 with all other ports closed. Given the powerful position of these nameservers it is important to have as little surface area as possible. Any additional services exposed such as HTTP, SSH, or SMTP are all additional pathways for an attacker to exploit in order to compromise the given TLD/domain extension.
This section is a bit awkward because I want to outline how dire the situation is without encouraging any malicious activity. During the course of this investigation there were a few situations where simply browsing things like websites hosted on the TLD nameservers led to strong indicators of both exploitability and in some cases even previous compromise. I will be omitting these and focusing only on some key examples to demonstrate the point.
Finger
The finger protocol was written in 1971 by Les Earnest to allow users to check the status of a user on a remote computer. This is an incredibly old protocol which is no longer used on any modern systems. The idea of the protocol is essentially to answer the question of “Hey, is Dave at his machine right now? Is he busy?”. With finger you can check into the remote user’s login name, real name, terminal name, idle time, login time, office location and office phone number. As an example, we’ll finger one of the authoritative nameservers for the country of Bosnia and see what the root user is up to:
bash-3.2$ finger -l [email protected]
[202.29.151.3]
Login: root Name: Charlie Root
Directory: /root Shell: /bin/sh
Last login Sat Dec 14 16:41 2013 (ICT) on console
No Mail.
No Plan.
Looks like root has been away for a long time! Let’s take a look at one of the nameservers for Vietnam:
bash-3.2$ finger -l [email protected]
[203.119.60.105]
Login name: nobody In real life: NFS Anonymous Access User
Directory: /
Never logged in.
No unread mail
No Plan.
Login name: noaccess In real life: No Access User
Directory: /
Never logged in.
No unread mail
No Plan.
Login name: nobody4 In real life: SunOS 4.x NFS Anonymous Access User
Directory: /
Never logged in.
No unread mail
No Plan.
Login name: named In real life: User run named
Directory: /home/named Shell: /bin/false
Never logged in.
No unread mail
No Plan.
bash-3.2$
bash-3.2$ finger -l [email protected]
[203.119.60.105]
Login name: root In real life: Super-User
Directory: / Shell: /sbin/sh
Last login Tue Sep 30, 2014 on pts/1 from DNS-E
No unread mail
No Plan.
This one is more recent with a last login date for root of September 30, 2014. The fact that this protocol is installed on these nameservers likely indicates just how old these servers are.
**Dynamic Websites
**
Probably the most common open nameserver port next to 53 was port 80 (HTTP). Some of the most interesting results came from simply visiting these websites. For example, one nameserver simply redirected me to an ad network:
* Rebuilt URL to: http://93.190.140.242/
* Trying 93.190.140.242...
* Connected to 93.190.140.242 (93.190.140.242) port 80 (#0)
> GET / HTTP/1.1
> Host: 93.190.140.242
> Accept: */*
> User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:45.0) Gecko/20100101 Firefox/45.0
>
< HTTP/1.1 302 Moved Temporarily
< Server: nginx/1.10.1
< Date: Sun, 04 Jun 2017 03:16:30 GMT
< Content-Type: text/html
< Transfer-Encoding: chunked
< Connection: close
< X-Powered-By: PHP/5.3.3
< Location: http://n158adserv.com/ads?key=6c6004f94a84a1d702c2b8dc16052e50&ch=140.242
<
* Closing connection 0
I’m still unsure if this was a compromised nameserver or if the owner was just trying to make some extra money off of sketchy ads.
Other nameservers (such as one of the Albania nameservers for .com.al, .edu.al, .mil.al, .net.al, and .nic.al) returned various configuration pages which print verbose information about the machine they run on:
 The party wouldn’t be complete without the ability to run command-line utilities on the remote server (nameserver for .ke, .ba, and a handful of other extensions):
The party wouldn’t be complete without the ability to run command-line utilities on the remote server (nameserver for .ke, .ba, and a handful of other extensions):
 **And much much more…
**And much much more…
**
Additionally there are many other fun services which I won’t go too into much detail for brevity. Things like SMTP, IMAP, MySQL, SNMP, RDP are all not at all uncommon ports to be open on various domain extension nameservers. Given the large attack surface of these services I would rate the chances of this route succeeding very highly, however we won’t engage in any further testing given that we don’t want to act maliciously. Sadly due to the sheer number of nameservers running outdated and insecure software responsible disclosure to all owners would likely be an endless endeavor.
Checking for Expired TLD & Extension Nameserver Domain Names
This avenue was something I was fairly sure was going to be the route to victory so I spent quite a lot of time building out tooling to check for vulnerabilities of this type. The process for this is essentially to enumerate all nameserver hostnames for a given extension and then checking to see if any of the base-domains were expired and available for registration. The main issue I ran into is many registries will tell you that a domain is totally available until you actually attempt to purchase it. Additionally there were a few instances where a nameserver domain was expired but for some reason the domain was still unavailable for registration despite not being marked as reserved. This scanning lead to the enumeration of many domain takeovers under restricted TLD/domain extension space (.gov, .edu, .int, etc) but none in the actual TLD/domain extensions themselves.
Examining Hosted TLD & Extension Nameserver for DNS Errors
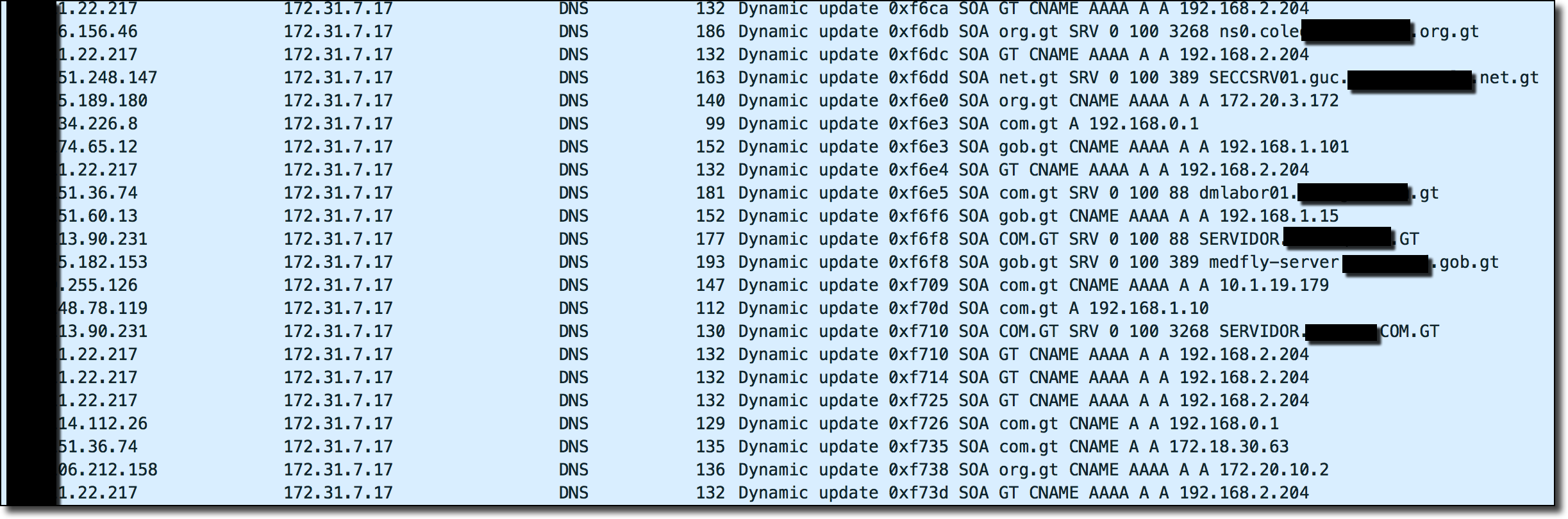
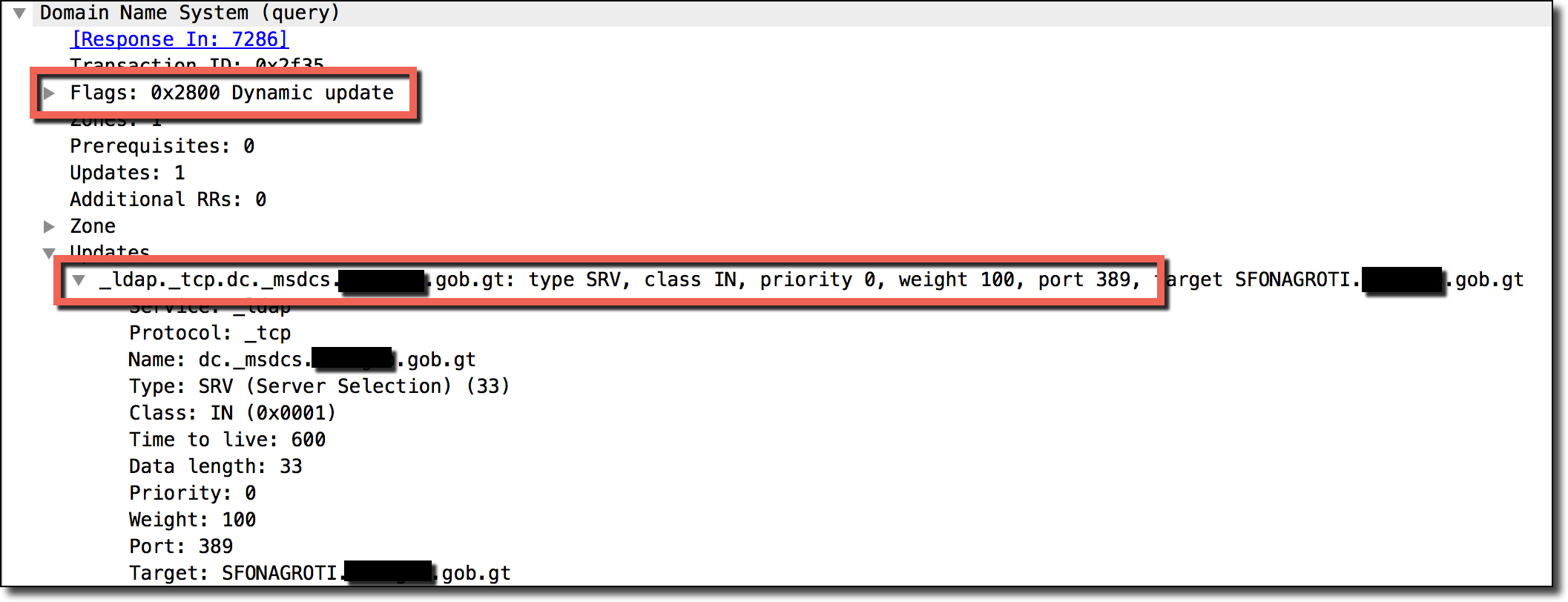
One useful tool for finding vulnerabilities (even ones you didn’t even know existed) is to scan for general DNS errors and misconfigurations and investigate the anomalies you find. One useful tool for this is ZoneMaster which is a general DNS configuration scanning tool which has tons and tons of tests for misconfigurations of nameservers/DNS. I tackled this approach by simply scripting up ZoneMaster scans for all of the domain extensions listed in the public suffix list. Pouring over and grepping through the results led to some pretty interesting findings. One finding is listed in a previous blog post (in the country of Guatemala’s TLD .gt) and another is shown below.
Striking Paydirt – Finding Vulnerabilities Amongst the Errors
After scripting the ZoneMaster tool to automate scanning all of the TLD/domain extensions in the public suffix list I found one particularly interesting result. When scanning over the results I found that one of the nameservers for the .co.ao extension was serving a DNS REFUSED error code when requesting the nameservers for the .co.ao zone:
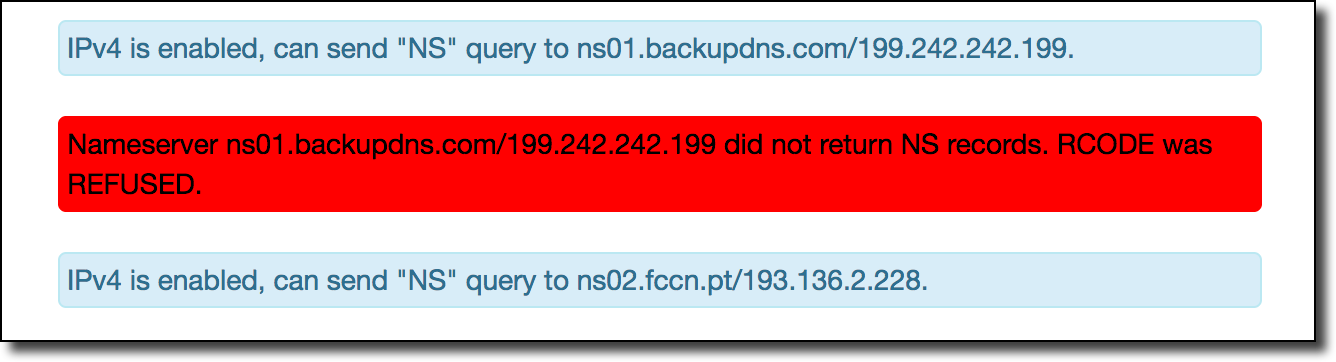 A quick verification with dig confirmed that this was indeed the case:
A quick verification with dig confirmed that this was indeed the case:
$ dig NS co.ao @ns01.backupdns.com.
; <<>> DiG 9.8.3-P1 <<>> NS co.ao @ns01.backupdns.com.
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 21693
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;co.ao. IN NS
;; Query time: 89 msec
;; SERVER: 199.242.242.199#53(199.242.242.199)
;; WHEN: Thu Feb 9 21:57:35 2017
;; MSG SIZE rcvd: 23
The nameserver in question, ns01.backupdns.com, appeared to be run by a third party DNS hosting service called Backup DNS:
 After some examination of this site it appeared to be a fairly aged DNS hosting service with an emphasis on hosting backup DNS servers in case of a failure on the primary nameserver. What piqued my interest to investigate was the DNS error code REFUSED which is often used as a response error when the nameserver simply does not have a zone stored for the specified domain (in this case the .co.ao domain). This is often dangerous because hosted DNS providers will often allow for DNS zones to be set up by any account with no verification of domain name ownership, meaning that anyone could create an account and a zone for .co.ao to potentially serve entirely new records.
After some examination of this site it appeared to be a fairly aged DNS hosting service with an emphasis on hosting backup DNS servers in case of a failure on the primary nameserver. What piqued my interest to investigate was the DNS error code REFUSED which is often used as a response error when the nameserver simply does not have a zone stored for the specified domain (in this case the .co.ao domain). This is often dangerous because hosted DNS providers will often allow for DNS zones to be set up by any account with no verification of domain name ownership, meaning that anyone could create an account and a zone for .co.ao to potentially serve entirely new records.
Interested in seeing if this was possible I created an account on the website and turned their documentation page:
 Given the name of the site the set up instructions made sense. In order to create a zone for the .co.ao zone I had to first add the zone to my account via the domain management panel:
Given the name of the site the set up instructions made sense. In order to create a zone for the .co.ao zone I had to first add the zone to my account via the domain management panel:
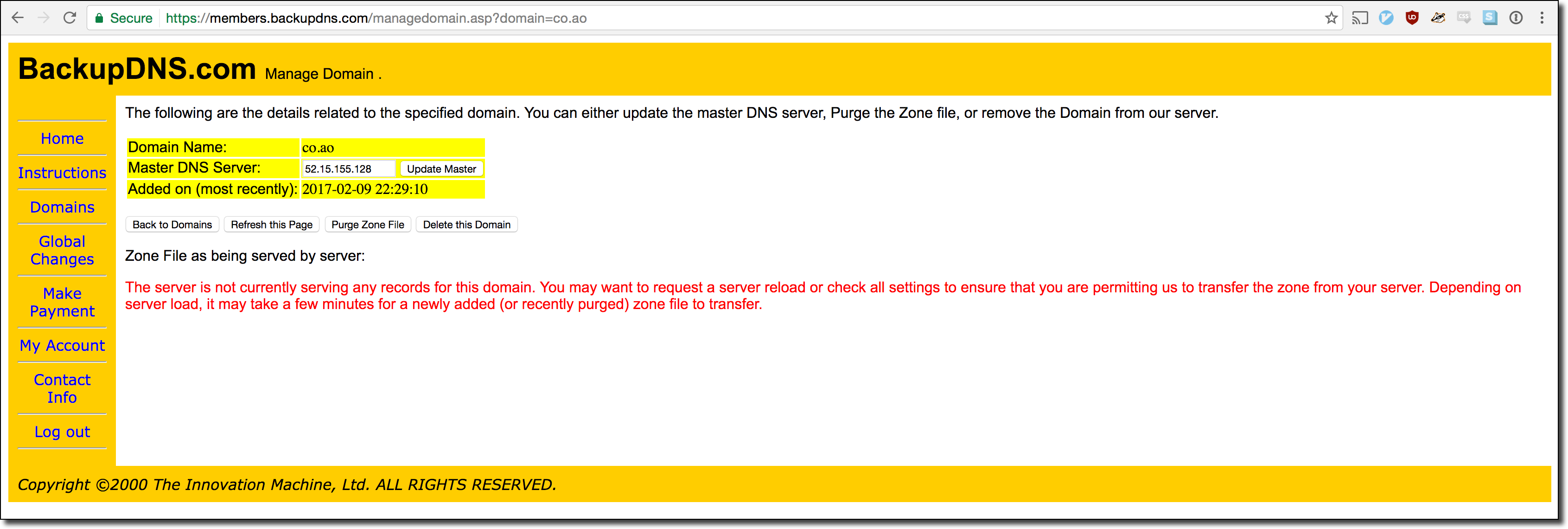 This worked without any verification but there was still no zone data loaded for that particular zone. The next steps were to set up a BIND server on a remote host and configure it to be an authoritative nameserver for the .co.ao zone. Additionally, the server had to be configured to allow zone transfers from the BackupDNS nameserver so that the zone data could be copied over. The following diagrams show this process in action:
This worked without any verification but there was still no zone data loaded for that particular zone. The next steps were to set up a BIND server on a remote host and configure it to be an authoritative nameserver for the .co.ao zone. Additionally, the server had to be configured to allow zone transfers from the BackupDNS nameserver so that the zone data could be copied over. The following diagrams show this process in action:
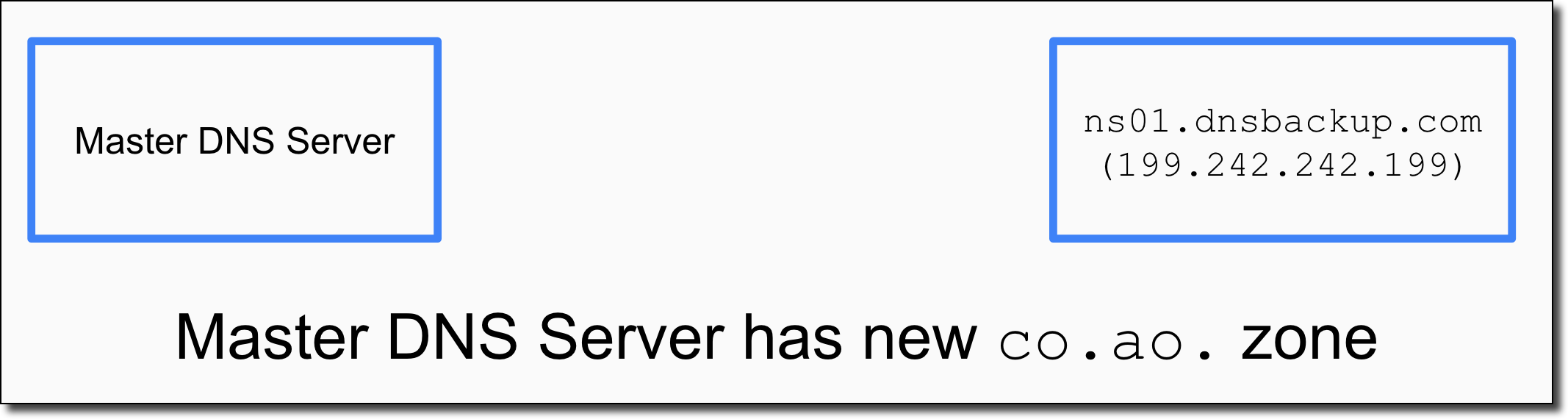 We start with our Master DNS Server (in this case a BIND server set up in AWS) and the target BackupDNS nameserver we want our zone to be copied into.
We start with our Master DNS Server (in this case a BIND server set up in AWS) and the target BackupDNS nameserver we want our zone to be copied into.
 On a regular interval the BackupDNS nameserver will issue a zone transfer request (the AXFR DNS query). This is basically the nameserver asking “Can I have a copy of all the DNS data you have for .co.ao?“.
On a regular interval the BackupDNS nameserver will issue a zone transfer request (the AXFR DNS query). This is basically the nameserver asking “Can I have a copy of all the DNS data you have for .co.ao?“.
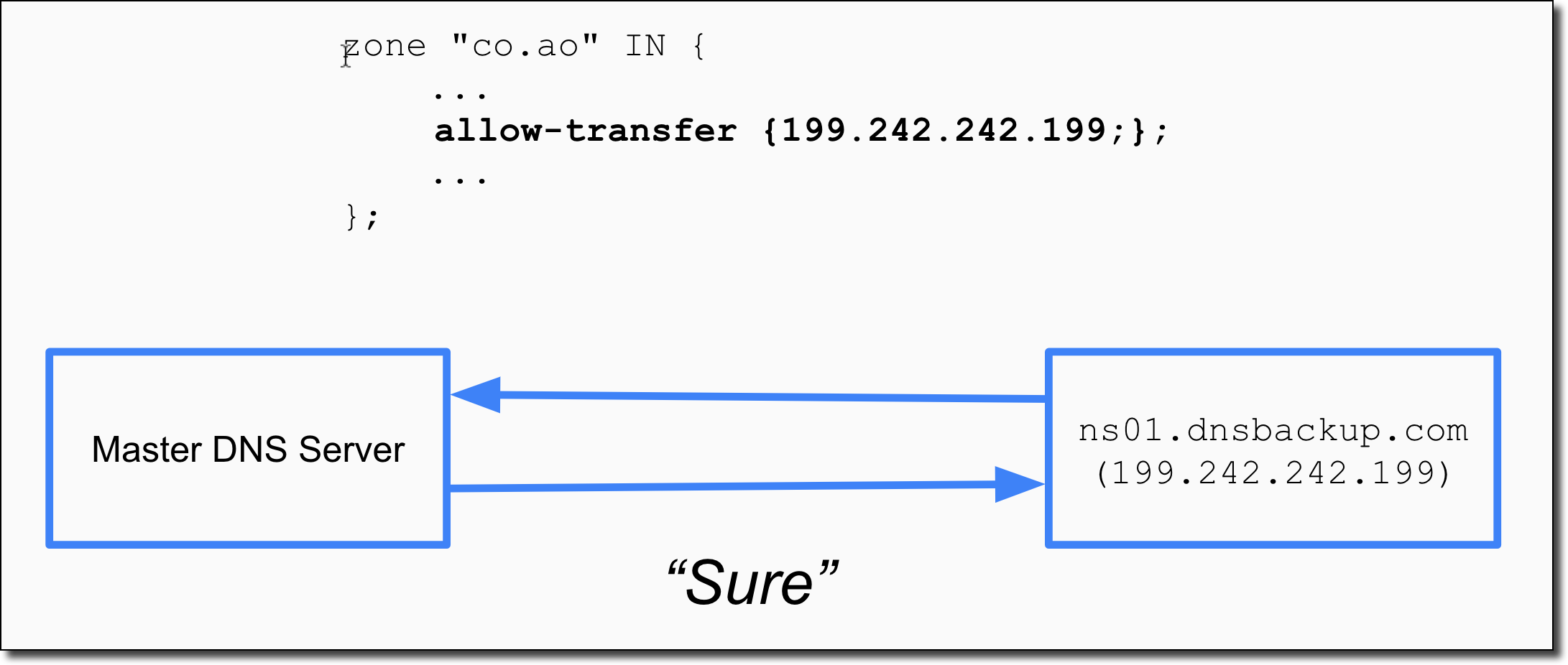 Since we’ve configured our master nameserver to allow zone transfers from the BackupDNS nameserver via the allow-transfer configuration in BIND the request is granted and the zone data is copied over. We have now created the proper .co.ao zone in the BackupDNS service!
Since we’ve configured our master nameserver to allow zone transfers from the BackupDNS nameserver via the allow-transfer configuration in BIND the request is granted and the zone data is copied over. We have now created the proper .co.ao zone in the BackupDNS service!
Ok, so I’d like to pause for just a moment and point out that at this point, I really wasn’t thinking that this would work. This wasn’t the first time I’d tested for issues like this with various nameservers and previous attempts had ended unsuccessfully. That being said, just in case it did work the zone I had copied over was intentionally made with records that had a TTL of 1 second and a SOA record of only 60 seconds. This means that the records would be thrown quickly out of the cache and the DNS request would me remade shortly to another nameserver which was a legitimate one for the extension. If you ever undertake any testing of this nature I highly recommend you do the same in order to minimize caching bad DNS responses for people trying to access the target legitimately.
It, of course, did work and the BackupDNS nameserver immediately began serving DNS traffic for .co.ao. After I saw the service confirm the copy I did a quick query with dig to confirm:
$ dig NS google.co.ao @ns01.backupdns.com
; <<>> DiG 9.8.3-P1 <<>> NS google.com.ao @ns01.backupdns.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 37564
;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;google.co.ao. IN NS
;; AUTHORITY SECTION:
co.ao. 60 IN SOA root.co.ao. root.co.ao. 147297980 900 900 1800 60
;; Query time: 81 msec
;; SERVER: 199.242.242.199#53(199.242.242.199)
;; WHEN: Sun Feb 12 23:13:50 2017
;; MSG SIZE rcvd: 83
Uh oh, that’s not good. I had originally placed a few NS records in the BIND zone file with the intention of delegating the DNS queries back to the legitimate nameservers but I screwed up the BIND config and instead of replying with a DNS referral the server replied with an authoritative answer of NXDOMAIN. This is obviously not great so I quickly deleted the zone from the BackupDNS service. Due to some annoying caching behavior of the BackupDNS service this took a few minutes longer than I would’ve liked but soon enough the service was again returning REFUSED for all queries for .co.ao. Luckily this took all took place at ~3:00 AM Angola time, this combined with the long TTL for the .co.ao TLD likely meant that very few users were actually impacted by the event (if any).
Phew.
Despite the road bump this confirmed that the extension was indeed vulnerable. I then turned back to the scan results I had collected and found that not only was .co.ao vulnerable but .it.ao, nic.ao, and reg.it.ao were vulnerable as well! it.ao is another domain extension for the country of Angola which is commonly used for out-of-country entities. reg.it.ao is the organization that runs the .it.ao and .co.ao extensions.
Given the large impact that could occur if these extensions were hijacked maliciously I decided to block other users from being able to add these zones to their own BackupDNS accounts. I added all the extensions to my own account but did not create any zone data for them, this ensured they were still returned the regular DNS errors with no results while still preventing further exploitation:
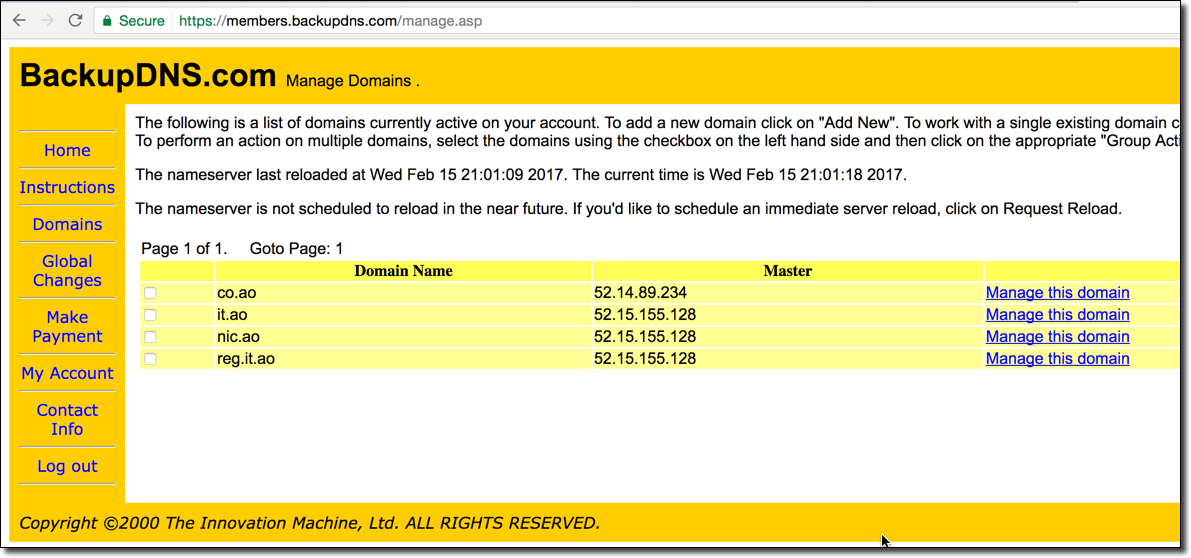 After preventing immediate exploitation I then attempted to reach out to the owners of the .co.ao and .it.ao extensions. For more information on the disclosure process please see “Responsible Disclosure Timeline” below.
After preventing immediate exploitation I then attempted to reach out to the owners of the .co.ao and .it.ao extensions. For more information on the disclosure process please see “Responsible Disclosure Timeline” below.
Hijacking a TLD – Compromising the .na TLD via WHOIS
While hijacking a nameserver for a domain extension is pretty useful for exploitation, there is a higher level of compromise that TLDs specifically can suffer from. Ownership of a TLD is outlined by the contacts listed on the WHOIS record which is hosted at the IANA Root Zone Database. As an attacker our main interest would be in getting the nameservers switched over to our own malicious nameservers so that we can serve up alternative DNS records for the TLD. IANA has a procedure for initiating this change for ccTLDs which can be found here. The important excerpt from this is the following:
The IANA staff will verify authorization/authenticity of the request and obtain confirmation from the listed TLD administrative and technical contacts that those contacts are aware of and in agreement with the requested changes. A minimum authentication of an exchange of e-mails with the e-mail addresses registered with the IANA is required.
The key note to make is that IANA will allow a nameserver change to be made for a TLD (just complete this form) if both the admin and technical contact on the WHOIS confirm via email that they want the change to occur.
In the interest of testing the security of this practice I enumerated all of the TLD WHOIS contact email address domains and used the TrustTrees script I wrote to look for any errors in the DNS configurations of these domains. After reading through pages of diagrams I found something interesting in the DNS for the .na TLD’s contact email domain (na-nic.com.na). The following is a diagram of the delegation paths for that domain:
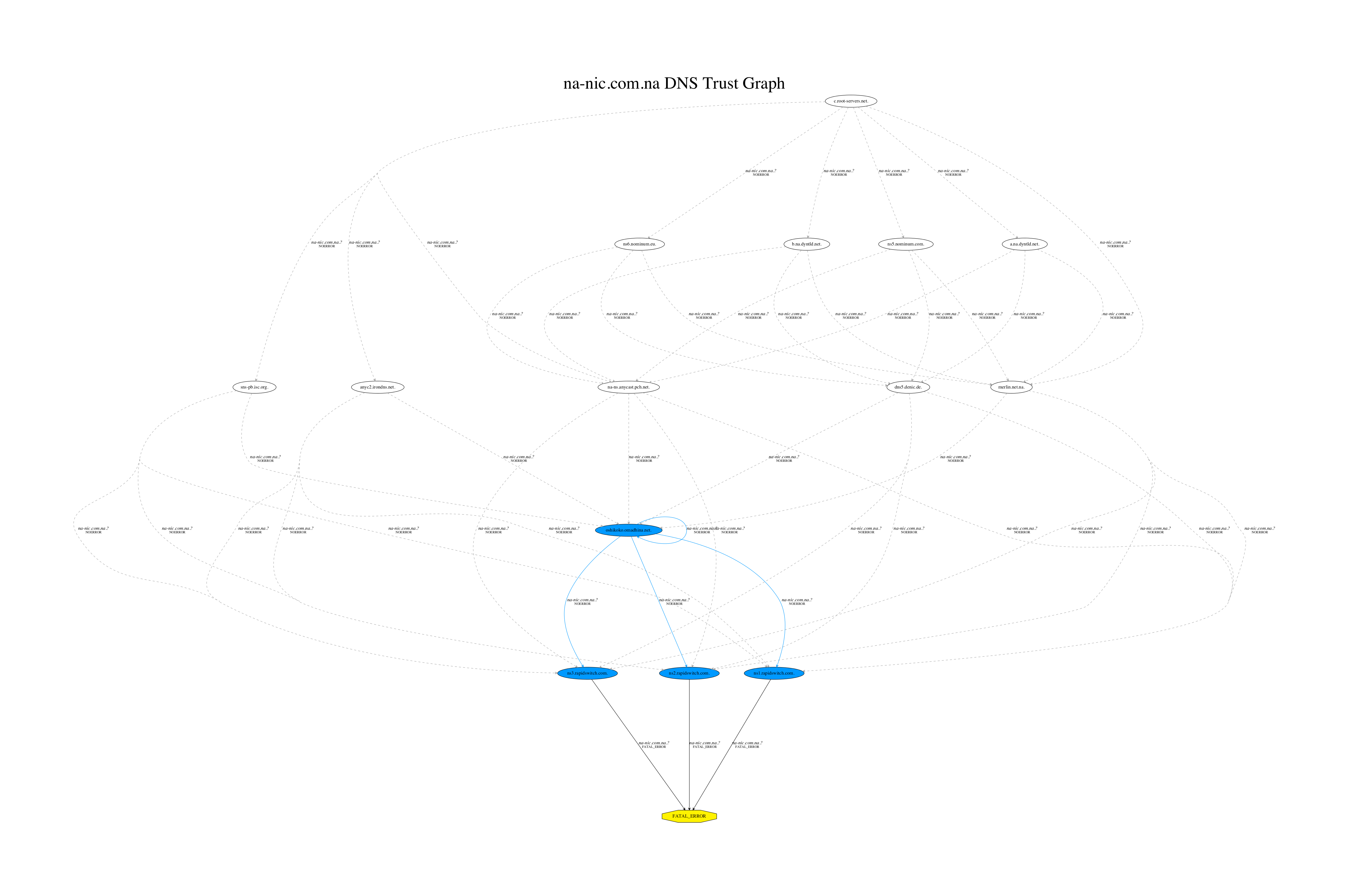 The relevant section of this graph being the following:
The relevant section of this graph being the following:
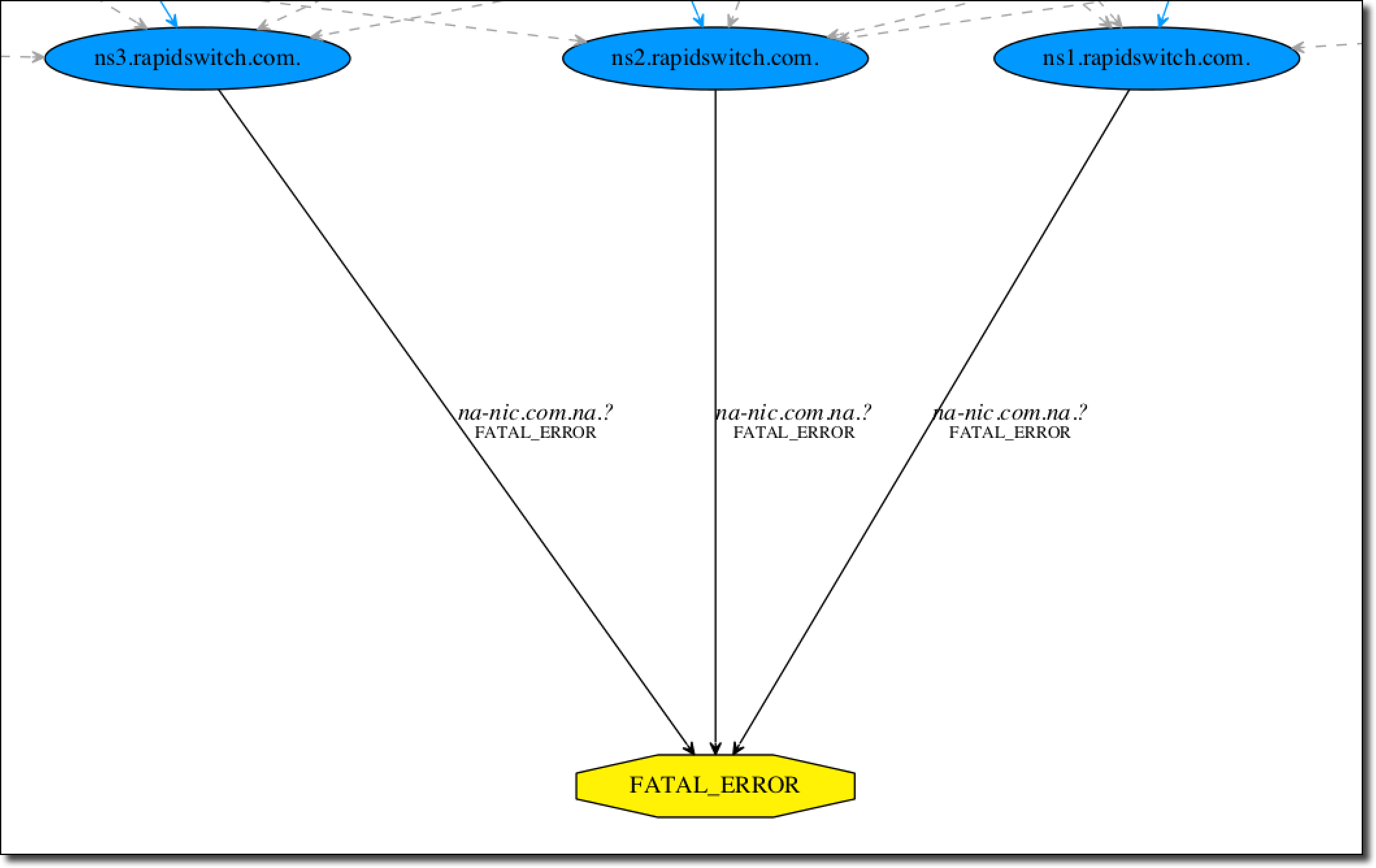 As can be seen above, three nameservers for the domain all return fatal errors when queried. These nameservers, ns1.rapidswitch.com, ns2.rapidswitch.com and ns3.rapidswitch.com all belong to the managed DNS provider RapidSwitch. If we do a query in dig we can see the specific details of the error being returned:
As can be seen above, three nameservers for the domain all return fatal errors when queried. These nameservers, ns1.rapidswitch.com, ns2.rapidswitch.com and ns3.rapidswitch.com all belong to the managed DNS provider RapidSwitch. If we do a query in dig we can see the specific details of the error being returned:
$ dig NS na-nic.com.na @ns1.rapidswitch.com.
; <<>> DiG 9.8.3-P1 <<>> NS na-nic.com.na @ns1.rapidswitch.com.
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 56285
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;na-nic.com.na. IN NS
;; Query time: 138 msec
;; SERVER: 2001:1b40:f000:41::4#53(2001:1b40:f000:41::4)
;; WHEN: Fri Jun 2 01:13:03 2017
;; MSG SIZE rcvd: 31
The nameserver replies with a DNS REFUSED error code. Just as with the Angola domain extensions this error code can indicate that the domain is vulnerable to takeover if the managed DNS provider does not properly validate domains before users add them to their account. To investigate I created a RapidSwitch account and navigated to the “My Domains” portion of the website:
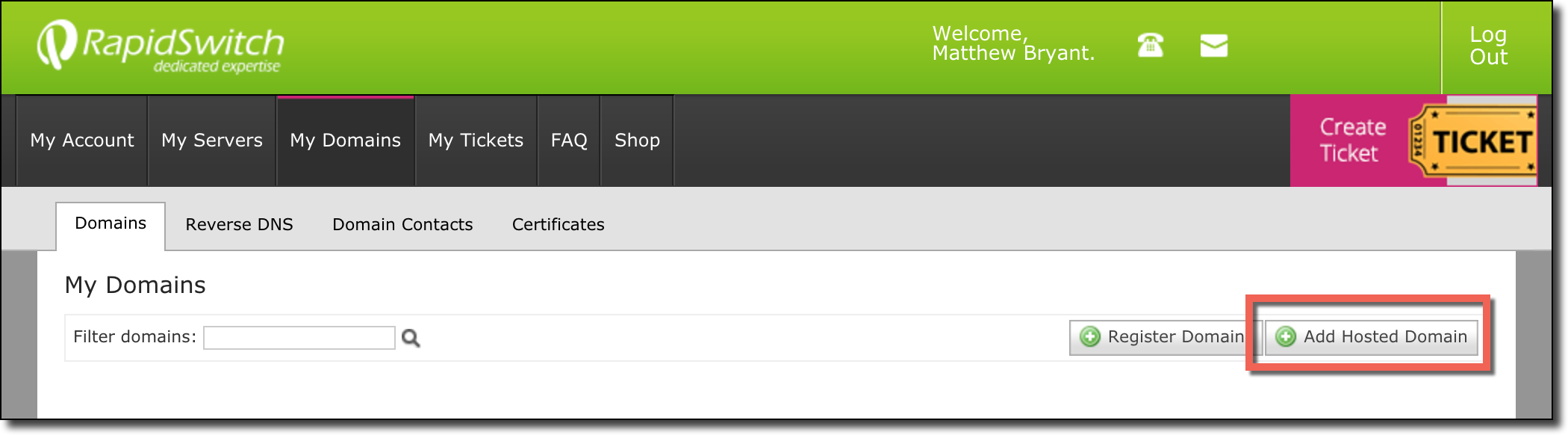 The “My Domains” section contained an “Add Hosted Domain” button which was exactly what I was looking to do.
The “My Domains” section contained an “Add Hosted Domain” button which was exactly what I was looking to do.
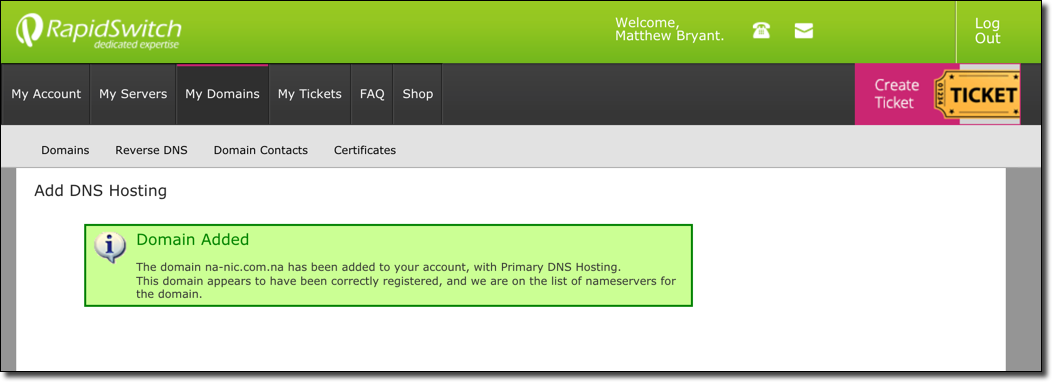 By completing this process I was able to add the domain to my account without any ownership verification. It appeared that the only verification that occurs is a check to ensure that RapidSwitch is indeed listed as a nameserver for the specified domain.
By completing this process I was able to add the domain to my account without any ownership verification. It appeared that the only verification that occurs is a check to ensure that RapidSwitch is indeed listed as a nameserver for the specified domain.
Having the domain in my account was problematic because I then had to replicate the DNS setup of the original nameserver in order to prevent interruptions to the domain’s DNS (which hosts email, websites, etc for na-nic.com.na). Deleting the domain from my account would’ve made the domain vulnerable to takeover again so I had to clone the existing records as well.
Once the records were created I added some records for proof.na-nic.com.na in order to verify that I had indeed successfully hijacked the DNS for the domain. The following dig query shows the results:
$ dig ANY proof.na-nic.com.na @ns2.rapidswitch.com
; <<>> DiG 9.8.3-P1 <<>> ANY proof.na-nic.com.na @ns2.rapidswitch.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 49573
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 4, ADDITIONAL: 4
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;proof.na-nic.com.na. IN ANY
;; ANSWER SECTION:
proof.na-nic.com.na. 300 IN A 23.92.52.47
proof.na-nic.com.na. 300 IN TXT "mandatory was here"
;; AUTHORITY SECTION:
na-nic.com.na. 300 IN NS ns1.rapidswitch.com.
na-nic.com.na. 300 IN NS ns3.rapidswitch.com.
na-nic.com.na. 300 IN NS oshikoko.omadhina.net.
na-nic.com.na. 300 IN NS ns2.rapidswitch.com.
;; ADDITIONAL SECTION:
ns1.rapidswitch.com. 1200 IN A 87.117.237.205
ns3.rapidswitch.com. 1200 IN A 84.22.168.154
oshikoko.omadhina.net. 3600 IN A 196.216.41.11
ns2.rapidswitch.com. 1200 IN A 87.117.237.66
;; Query time: 722 msec
;; SERVER: 2001:1b40:f000:42::4#53(2001:1b40:f000:42::4)
;; WHEN: Sat Jun 3 17:33:59 2017
;; MSG SIZE rcvd: 252
As can be seen above, the TXT record (and A record) is successfully returned indicating that the DNS hijacking issue is confirmed. In a real world attack the final step would be to DDoS the remaining legitimate nameserver to eliminate competition for DNS responses (a step we obviously won’t be taking)*.
After this I reached out to the .na TLD contacts to report the vulnerability and get it fixed as soon as possible. For more information on this disclosure timeline see the “Responsible Disclosure Timeline” section below.
*There is one more issue with our attack plan, unlike *.it.ao and *.co.ao the na-nic.com.na domain has DNSSEC enabled. This is actually something that I didn’t even notice at first because my resolver doesn’t support DNSSEC. After trying it on a few different networks it appears that almost every resolver I used does not actually enforce DNSSEC properly (which surprised me quite a bit). After doing some more research it appears that global adoption is quite low for DNS resolvers which explains this behavior. So, depending on resolver configurations our attack may be complicated by this issue! We’ll discuss this further in the final conclusions section below. That being said, nice job to the admin setting it up!
The Impact of a TLD/Domain Extension Takeover
Universal Authentication & International Domains
Despite these vulnerabilities affecting an extension for the country of Angola and Namibia the effects are much farther reaching than just these countries. For example, many popular online services will have multiple homepages with domain extensions of the local country/area to give the site a more local feeling. Many of these sites will tie all of these homepages together with a universal authentication flow that automatically logs the user into any of the homepage despite them all being separate domains.
One example of this is Google which has search homepages with many extensions (here is a link which appears to have aggregated them all). One of these, of course, is google.co.ao:
 Another being google.com.na:
Another being google.com.na:
 In order to provide a more seamless experience you can easily log yourself into any Google homepage (if you were already authenticated to Google on another homepage) by just clicking the blue button on the top right corner of the homepage. This button is just a link similar to the following:
In order to provide a more seamless experience you can easily log yourself into any Google homepage (if you were already authenticated to Google on another homepage) by just clicking the blue button on the top right corner of the homepage. This button is just a link similar to the following:
https://accounts.google.com/ServiceLogin?hl=pt-PT&passive=true&continue=https://www.google.co.ao/%3Fgws_rd%3Dssl
Visiting this link will result in a 302 redirect to the following URL:
https://accounts.google.co.ao/accounts/SetSID?ssdc=1&sidt=[SESSION_TOKEN]&continue=https://www.google.co.ao/?gws_rd=ssl&pli=1
This passes a session token in the sidt parameter which logs you into the google.co.ao domain and allows the authentication to cross the domain/origin barrier.
What this means for exploitation however, is that if you compromise any Google homepage domain extension (of which Google trusts approximate ~200) then you can utilize the vulnerability to begin hijacking any Google account from any region. This is a bizarre threat model because it’s quite likely that you’d be able to exploit one of the 200 domain extension nameservers/registries before you could get a working Google account exploit in their standard set of services. After all, Google has a large security team full of people constantly auditing their infrastructure where as many TLDs and domain extensions are just run by random and often small organizations.
This is simplifying it quite a bit of course. In order to actually abuse a DNS hijacking vulnerability of this type you would have to complete the following steps (all in a stealthy manner as to not get caught too quickly):
- Compromise a domain extension’s nameserver or registry to gain the ability to modify nameservers for your target’s website.
- Begin returning new nameservers which you control for your target domain with an extremely long TTL (BIND’s resolver supports up to a week by default). This is important so that we can get cached in as many resolvers as possible, we also want to set a low TTL for the actual A record resolution for the google.co.ao/google.com.na sub-domains so that we can switch these over quickly when we want to strike.
- Once we’ve heavily stacked the deck in our favor we must now get a valid SSL certificate for our google.co.ao/google.com.na domain name. This is one of the trickiest steps because certificate transparency can get us caught very quickly. The discussion around certificate transparency, and getting a certificate without being logged in certificate transparency logs is a long one but suffice to say that it’s not going to be as easy as it was.
- We now set up multiple servers to host the malicious google.co.ao/google.com.na site with SSL enabled and switch all of the A record responses to point to our malicious servers. We then begin our campaign to get as many Google users as possible to visit the above link to give us their authentication tokens, depending on the goal this may be a more targeted campaign, etc. One nice part about this attack is the victims don’t even have to visit the URL – any
![]() tag requests (e.g. anything that causes a GET request) will complete the 302 redirect and yield what we’re looking for.
tag requests (e.g. anything that causes a GET request) will complete the 302 redirect and yield what we’re looking for.
Widespread Affects – A Tangled Web
One other thing to consider is that not only are all *.co.ao, *.it.ao, and *.na domain names vulnerable to DNS hijacking but also anything that depends on these extensions may have become vulnerable as well. For example, other domains that utilize *.co.ao/*__.it.ao/*.na nameserver hostnames can be poisoned by proxy (though glue records may make this tricky). WHOIS contacts which reflect domains from these extensions are also in danger since WHOIS can be used to pull domains from owners and issue SSL certificates. Moving up the layers of the stack things like HTTP resource includes on websites reveal just how entangled the web actually is.
Conclusions & Final Thoughts
I hope that I’ve made a convincing argument that the security of domain extensions/TLDs is not infallible. Keep in mind that even with all of these DNS tricks the easiest method is likely just to exploit a vulnerability in a service running on a domain extension’s nameservers. In my opinion I believe the following steps should be taken by Internet authorities and the wider community to better secure the DNS:
- Require phone confirmation for high impact changes to TLDs in addition to the minimum requirement of email confirmation from the WHOIS contacts.
- Set more strict requirements for TLD nameservers – limiting exposure of ports to just UDP/TCP port 53.
- Perform continual automated auditing of TLD DNS and notify TLD operators upon detection of DNS errors.
- Inform domain owners about the risks of buying into various domain extensions/TLDs and keep a record of past security incidents so that people can make an informed decision when purchasing their domains. A high emphasis on things like response times and time to resolve the alleged security incidents are important to track as well.
- Raise greater awareness of DNSSEC and push DNS resolvers to support it. The adoption for DNSSEC is incredibly poor and if implemented by both the domain and the resolver being used it can thwart some of these hijacking issues (assuming the attacker hasn’t compromised the keys as well). Speaking from personal experience, I don’t even notice DNSSEC failures because virtually no network (mobile, home, etc) that I use actually enforces it. I won’t get into the longer arguments around DNSSEC as a whole but suffice to say it would definitely be an additional layer of protection against these attacks.
Given the political complications when it comes to ccTLDs some of the enforcement of policies is undoubtedly tricky. While I believe that the above list would improve security I also understand that actually ensuring these things happen is also tough especially with so many parties involved (it’s always easier said than done). That being said, it’s important to weigh the safety of the DNS against the appeasement of the parties involved. Given the incredibly large attack surface I’m surprised that compromise of TLDs/domain extensions isn’t a more frequent event.
Responsible Disclosure Timeline
Angola *.it.ao & *.co.ao Takeover Disclosure
- Febuary 14, 2017: Reached out via reg.it.ao contact form requesting security contact and PGP key to report vulnerability.
- Febuary 15, 2017: Reply received with PGP ID specified and PGP encryption requested.
- Febuary 15, 2017: Sent full details of vulnerability in PGP-encrypted email.
- Febuary 21, 2017: Emailed Google security team about account takeover issue due to co.ao hijacking advising they turn off universal homepage authentication flow for google.co.ao to prevent Google accounts from being hijacked.
- Febuary 22, 2017: Emailed BackupDNS owner requesting help to block these zones from being added to arbitrary BackupDNS accounts.
- Febuary 22, 2017: BackupDNS owner replies stating he will put a block in place which requires admin approval to add zones to user accounts.
- Febuary 22, 2017: Confirmed with BackupDNS owner that I am no longer able to add the zones to my account.
- Febuary 24, 2017: Received reply stating the problem has been fixed by removing BackupDNS’s nameservers from the list of authoritative nameservers.
Namibia TLD *.na Takeover Disclosure
- June 3, 2017: Emailed the contacts on the .na WHOIS contact inquiring about the proper place to disclose a security vulnerability in the .na TLD’s WHOIS contact email domains.
- June 3, 2017: Received confirmation that the admin contact was the appropriate source to disclose this issue.
- June 3, 2017: Disclosed the issue to the admin contact.
- June 3, 2017: Vulnerability remediated by changing the nameservers for the na-nic.com.na domain and removing the RapidSwitch nameservers altogether.
Disclosure Note: This was an incredible turnaround time with the issue being received and fixed in just a few hours. In situations such as these I expect the turnaround to be weeks to months but due to the responsiveness of the operator this was remediated ASAP. Preventing all security issues isn’t possible but reacting quickly to existing ones with haste says a lot, hats off to the DNS admin of the .na TLD!

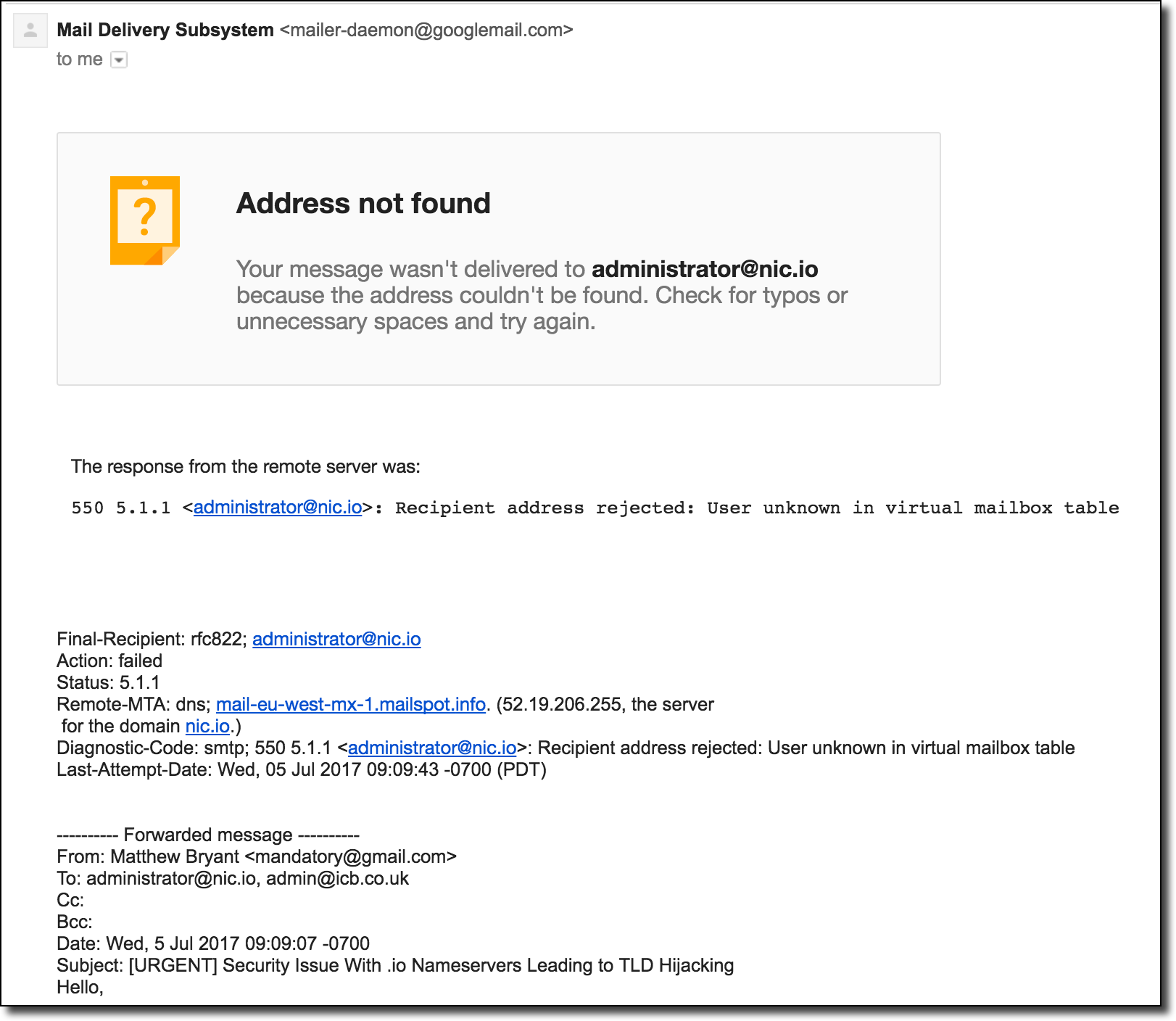
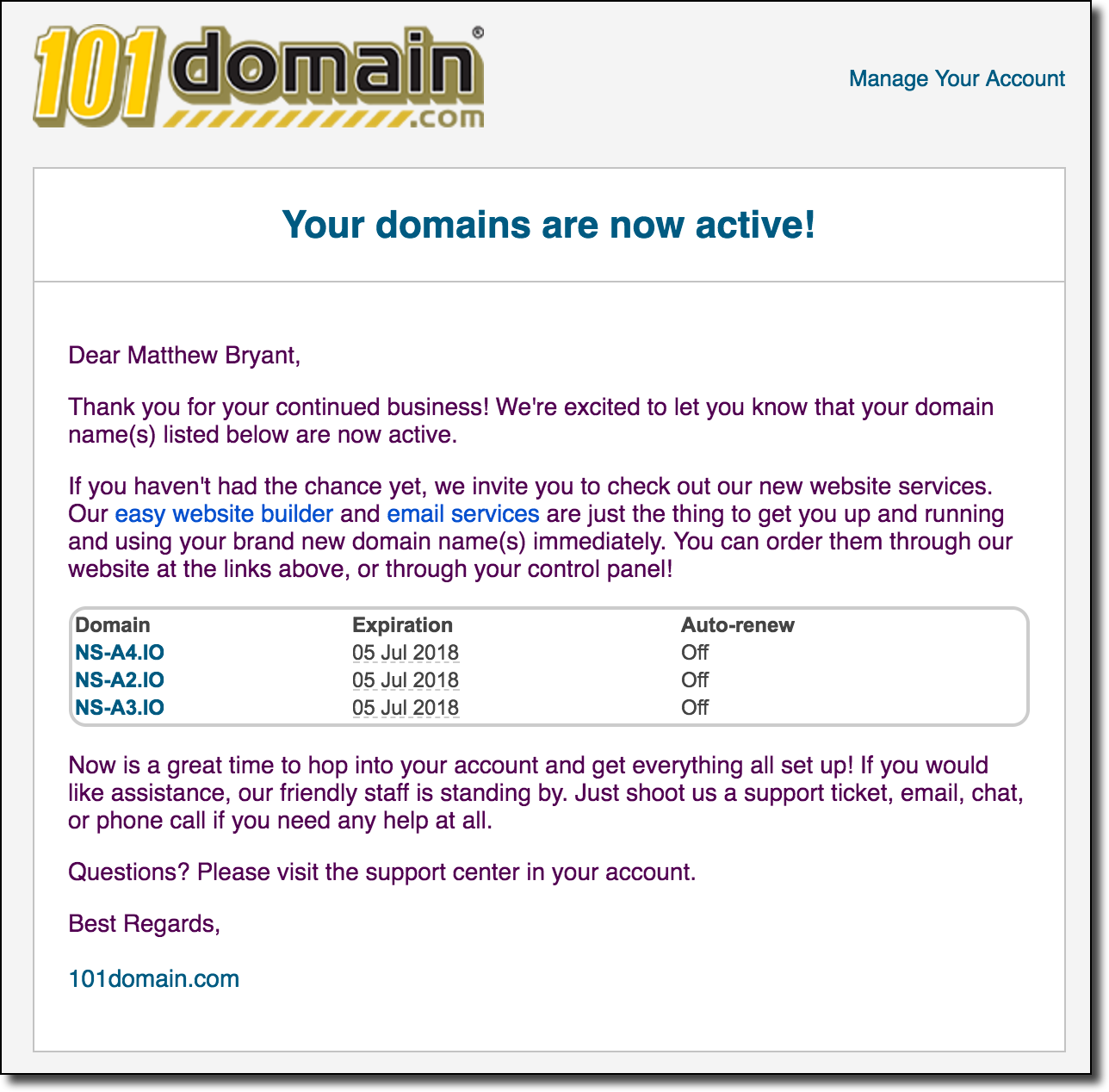
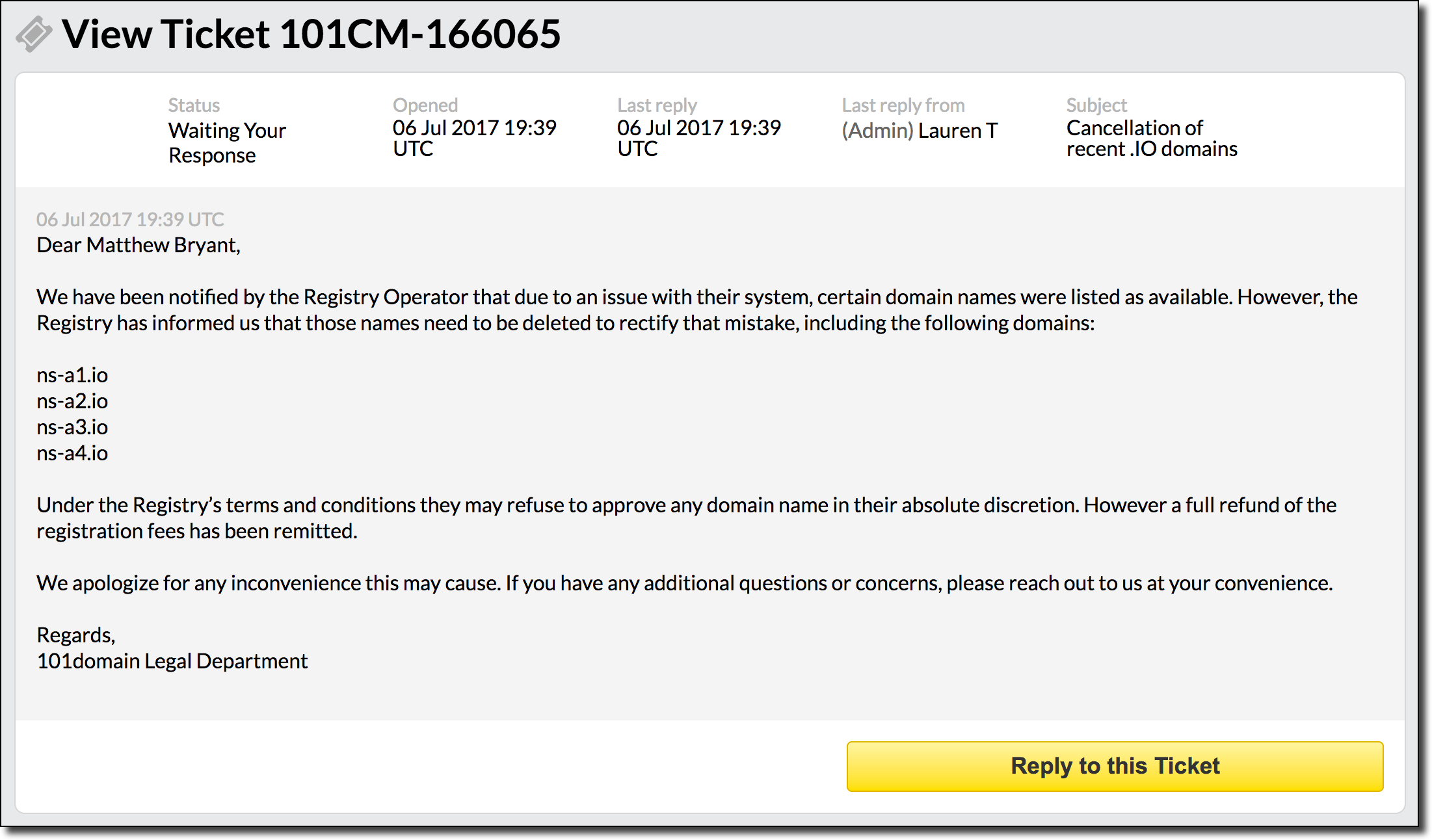



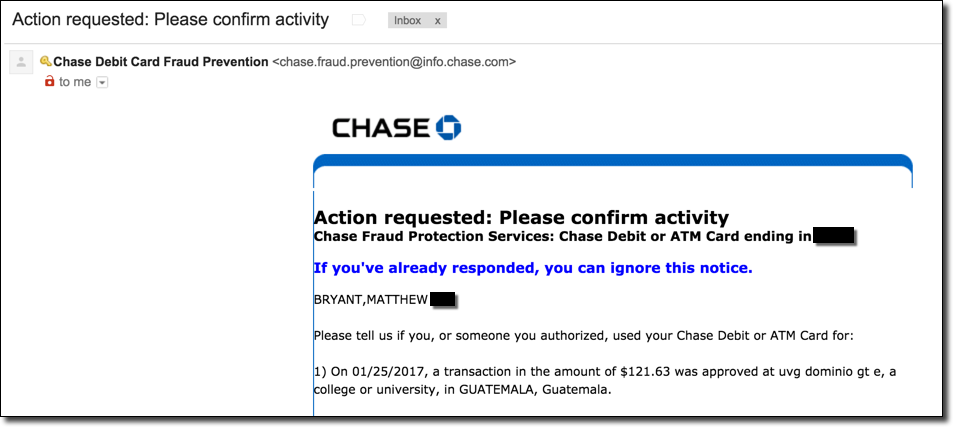 Apparently buying a Guatemalan domain name at 1:30 AM is grounds for your card being frozen.
Apparently buying a Guatemalan domain name at 1:30 AM is grounds for your card being frozen.